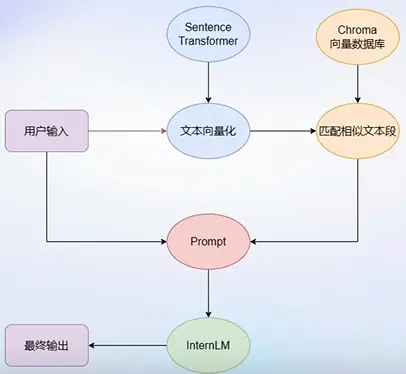
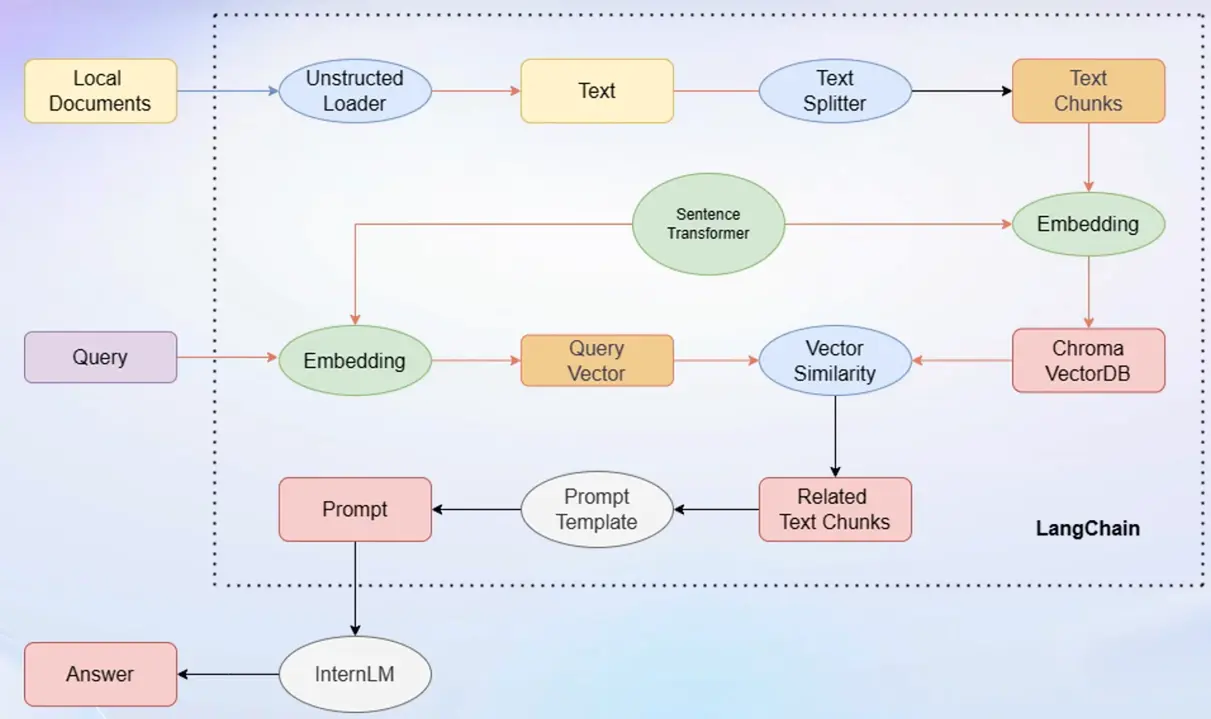
# 首先导入所需第三方库 from langchain.document_loaders import UnstructuredFileLoader from langchain.document_loaders import UnstructuredMarkdownLoader from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.vectorstores import Chroma from langchain.embeddings.huggingface import HuggingFaceEmbeddings from tqdm import tqdm import os
# 获取文件路径函数 def get_files(dir_path): # args:dir_path,目标文件夹路径 file_list = [] for filepath, dirnames, filenames in os.walk(dir_path): # os.walk 函数将递归遍历指定文件夹 for filename in filenames: # 通过后缀名判断文件类型是否满足要求 if filename.endswith(".md"): # 如果满足要求,将其绝对路径加入到结果列表 file_list.append(os.path.join(filepath, filename)) elif filename.endswith(".txt"): file_list.append(os.path.join(filepath, filename)) return file_list
def _call(self, prompt : str, stop: Optional[List[str]] = None, run_manager: Optional[CallbackManagerForLLMRun] = None, **kwargs: Any): # 重写调用函数 system_prompt = """You are an AI assistant whose name is InternLM (书生·浦语). - InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless. - InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文. """ messages = [(system_prompt, '')] response, history = self.model.chat(self.tokenizer, prompt , history=messages) return response @property def _llm_type(self) -> str: return "InternLM"
from langchain.vectorstores import Chroma from langchain.embeddings.huggingface import HuggingFaceEmbeddings import os from InternLM_LLM import InternLM_LLM from langchain.prompts import PromptTemplate from langchain.chains import RetrievalQA
def qa_chain_self_answer(self, question: str, chat_history: list = []): """ 调用问答链进行回答 """ if question == None or len(question) < 1: return "", chat_history try: chat_history.append( (question, self.chain({"query": question})["result"])) # 将问答结果直接附加到问答历史中,Gradio 会将其展示出来 return "", chat_history except Exception as e: return e, chat_history
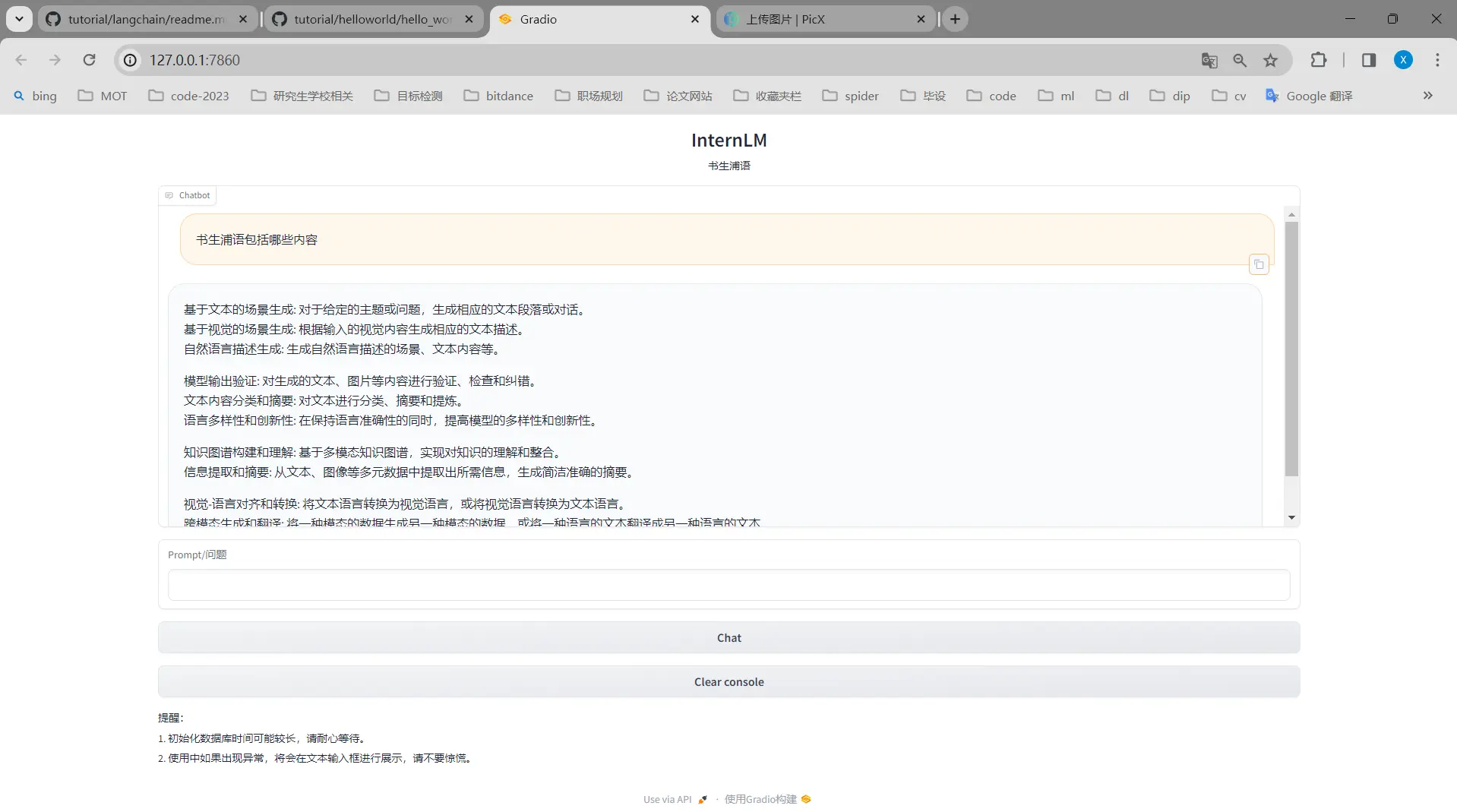
if __name__ == '__main__': import gradio as gr # 实例化核心功能对象 model_center = Model_center() # 创建一个 Web 界面 block = gr.Blocks() with block as demo: with gr.Row(equal_height=True): with gr.Column(scale=15): # 展示的页面标题 gr.Markdown("""<h1><center>InternLM</center></h1> <center>书生浦语</center> """)
with gr.Row(): with gr.Column(scale=4): # 创建一个聊天机器人对象 chatbot = gr.Chatbot(height=450, show_copy_button=True) # 创建一个文本框组件,用于输入 prompt。 msg = gr.Textbox(label="Prompt/问题")