Lecture3. 作业
1.基础作业:复现课程知识库助手搭建过程 (截图)
环境配置
环境准备
开发机创建
安装conda环境、安装依赖库
模型下载
- 下载internlm-chat-7b模型
LangChain 相关环境配置
- 安装LangChain依赖包
1 | pip install langchain==0.0.292 |
- 下载开源词向量模型 Sentence Transformer
- 在/root/code下创建LangChain文件下,在该文件夹下创建download_hf.py文件
1 | import os |

下载NLTK 相关资源
- 在使用开源词向量模型构建开源词向量的时候,需要用到第三方库
nltk的一些资源
- 在使用开源词向量模型构建开源词向量的时候,需要用到第三方库
1 | cd /root |

- 下载本项目代码
1 | cd /root |
知识库搭建
- 数据收集
1 | # 进入到数据库盘 |
加载数据
构建向量数据库
整体脚本
1 | # 首先导入所需第三方库 |

InternLM 接入 LangChain
- 为便捷构建 LLM 应用,我们需要基于本地部署的 InternLM,继承 LangChain 的 LLM 类自定义一个 InternLM LLM 子类,从而实现将 InternLM 接入到 LangChain 框架中。
1 | from langchain.llms.base import LLM |
构建检索问答链
- 加载向量数据库
- 实例化自定义 LLM 与 Prompt Template
- 构建检索问答链
- 三步的代码合在下面Web Demo里了
部署 Web Demo
1 | from langchain.vectorstores import Chroma |
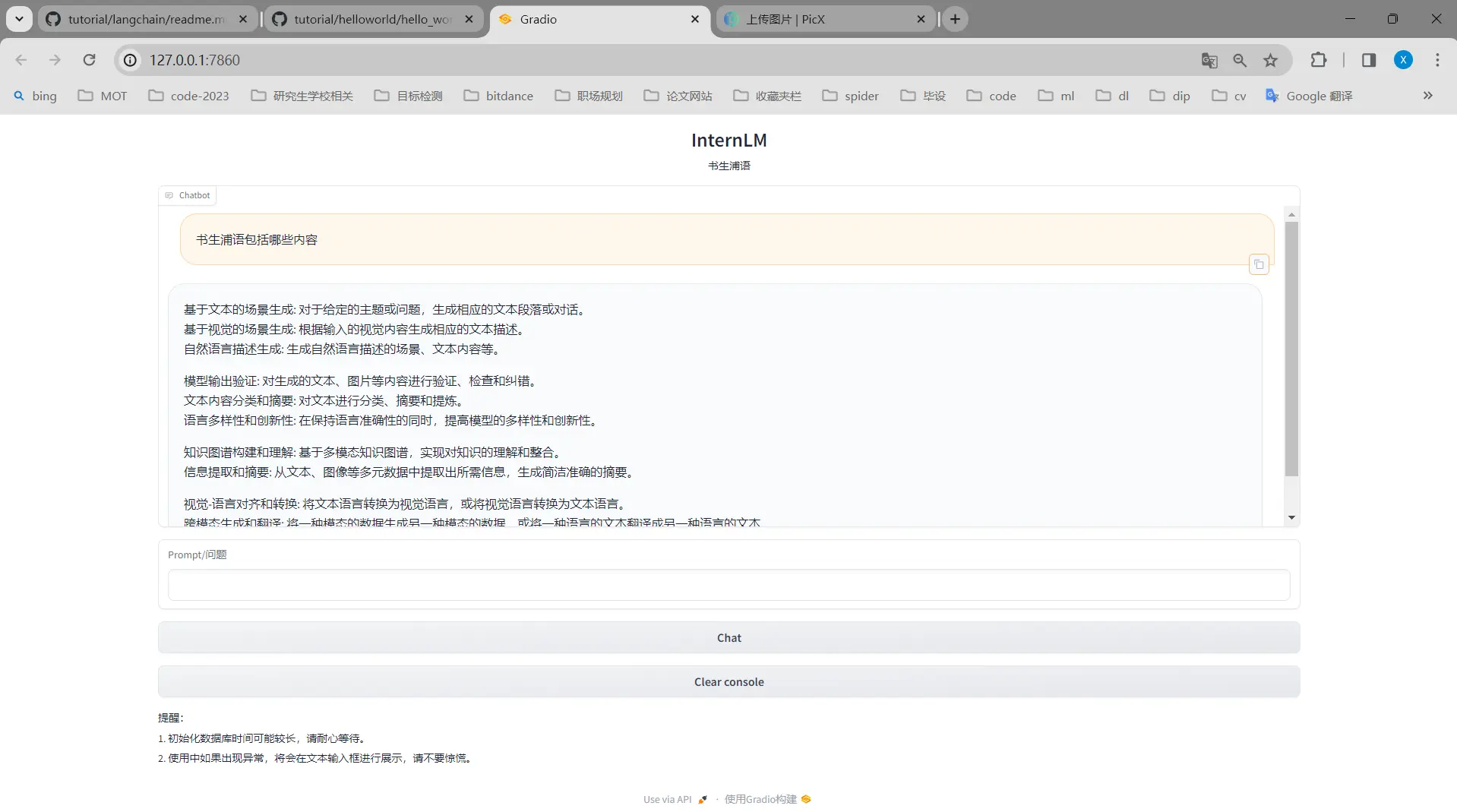
2.进阶作业:选择一个垂直领域,收集该领域的专业资料构建专业知识库,并搭建专业问答助手,并在 OpenXLab 上成功部署(截图,并提供应用地址)
目标
搭建一个多模态跟踪的数据库
过程
环境配置
延用基础作业的环境langchain,再加上一个pypdf库
1 | conda activate langchain |
知识库搭建
上传数据
1 | scp -r -P 34329 "D:/知云论文下载/vision-language tracking/cvpr2023- Joint Visual Grounding 引用" root@ssh.intern-ai.org.cn:/root/data/paper |
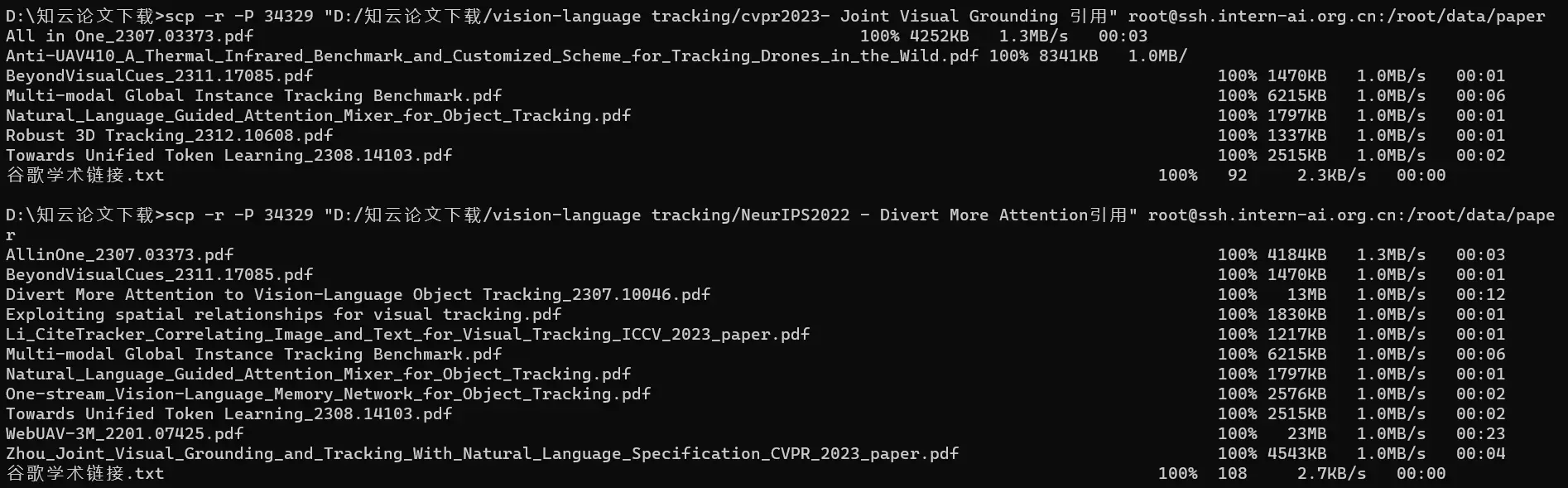
加载数据
构建数据库
整体脚本
1 | # 首先导入所需第三方库 |

和基础作业不同的是:
1.需要多导入两个库
1 | from langchain.document_loaders import PyPDFLoader # for loading the pdf |
2.导入pdf的函数
1 | if file_type == 'pdf': |
InternLM 接入 LangChain
构建检索问答链
- 加载向量数据库
- 实例化自定义 LLM 与 Prompt Template
- 构建检索问答链
- 三步的代码合在下面Web Demo里了
部署 Web Demo
1 | from langchain.vectorstores import Chroma |
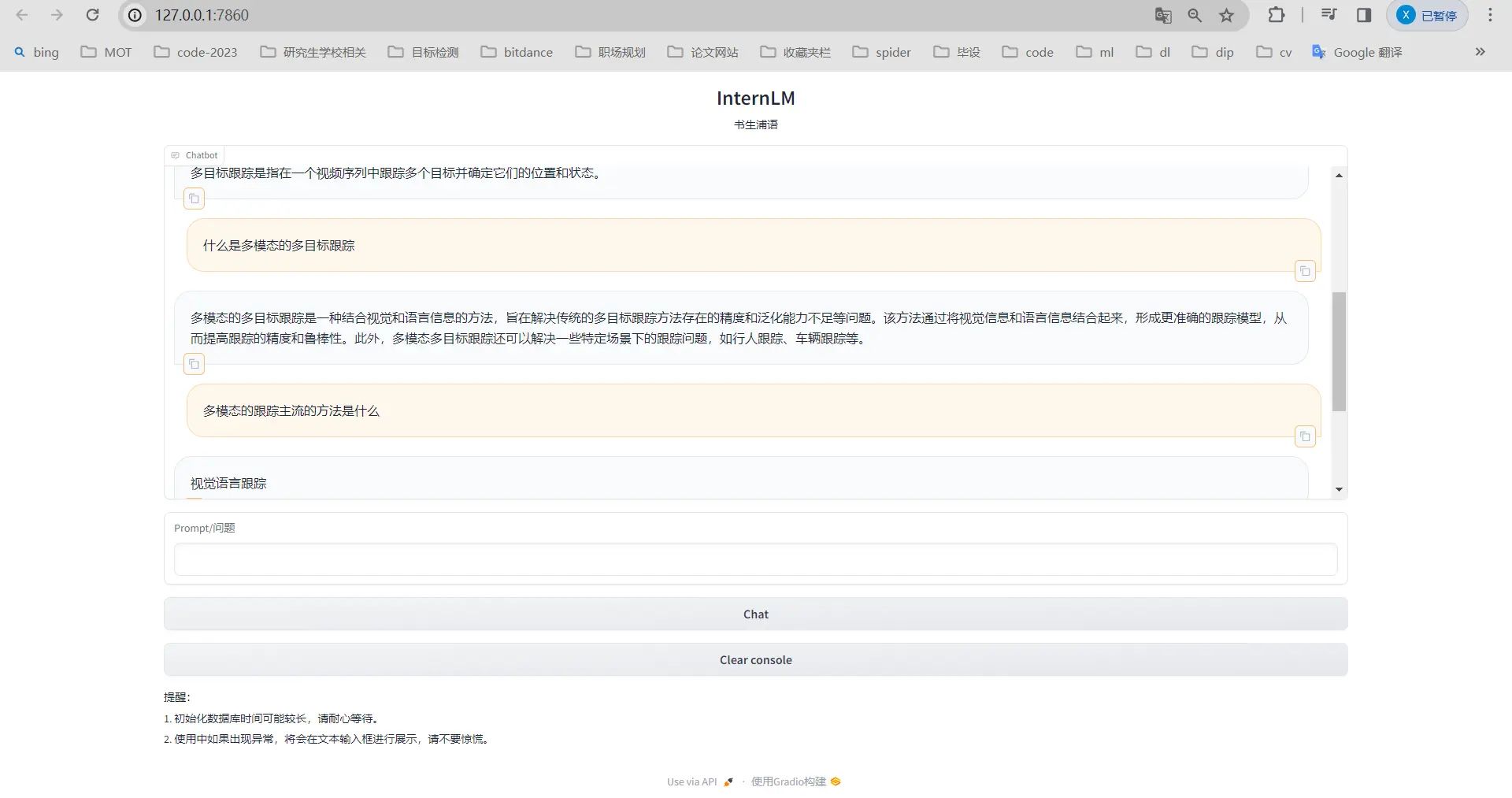
OpenXLAb没部署,之后有时间再弄。