在lesson3中,我们主要学习了两种大模型的开发范式,并详细学习了其中的RAG。本节课中,我们主要学习第二种范式,Finetune,并使用XTuner基于InternLM进行单卡微调。在普通的学习中,LLM没办法很好的应用于具体的实际和板块,因此需要微调来定制。对模型进行微调有两种策略,增加数据集和指令微调。XTuner是打包好的微调工具箱,它的微调原理是LoRA&QLoRA,能够减少显存占用,使开发者专注数据内容而不是格式。
XTuner概述
Finetune
Finetune是大模型常见的两种范式之一,它的核心:在已有数据集上微调
- 可以进行更多个性化微调,以满足用户需求。
- 需要在新的数据集上进行训练,这可能会导致成本上升。然而,这也意味着模型可以更好地适应不断变化的环境。
- 需要注意的是,由于训练成本较高,模型的更新可能不是实时的,但我们可以定期进行更新以确保其性能始终保持在最佳状态。
LLM
LLM就是大语言模型的统称。我们知道,LangChain封装了很多组件,通过将这些组件组合,一个chain能够封装一系列的LLM操作。
XTuner
XTuner是打包好的微调工具箱,支持Huggingface和modelscope加载模型和数据集。支持多款开源大模型InternLM,阿里千问,百川大模型,清华Chatglm,多专家模型等,加速算法等等都有。
微调框架Xtuner原理
Finetune简介
为什么要微调大语言模型?
- 在普通的学习中,LLM没办法很好的应用于具体的实际和板块,需要微调来定制!
常见的两种微调策略(训练数据的处理):
增量预训练
- 给模型投喂新知识,学更多有关目标领域的文本内容
- 不需要问题,只需要回答,都是陈述句
指令跟随微调
- 能让模型的输出更符合我们的意图
- 将pretrained LLM指令微调成instructed LLM
- Xtuner打包好的工具:指令跟随微调
- 构建对话模板,进行角色指定:将问题部分指定给user,将答案指定给assistant,给模型一个定位system
- 输入模型,计算答案assistant部分损失
Xtuner使用的微调原理:LoRA&QLoRA
Stable diffusion:不同的LoRA能够出不同的风格和人物
为什么要使用LoRA?什么是LoRA? 如果对整个模型的所有参数Linear都进行调整需要很大的显存,使用LoRA方法在原本的Linear旁新增一个分支,包含连续的两个小Linear(叫做Adapter),就能减少参数和显存开销。
全参数微调 VS LoRA VS QLoRA QLoRA使用4-bit模型加载器,不那么精确的加载模型。参数优化器能够在CPU和GPU之间调度。
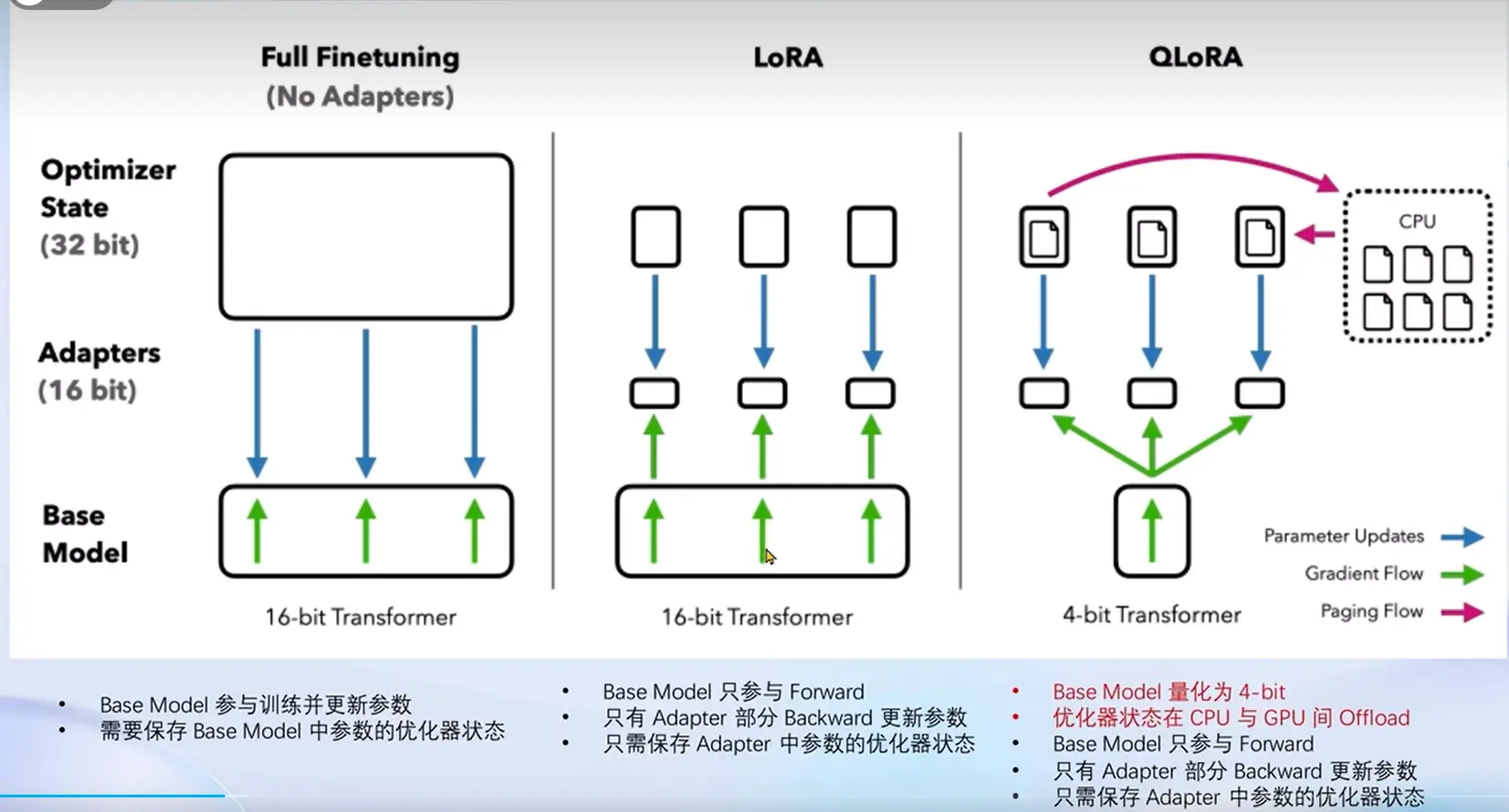
Xtuner微调工作流程
Xtuner有强大的数据处理引擎,使开发者专注数据内容而不是格式
数据处理流程:
1、原始问答对,格式化(数据集映射函数)
2、格式化问答对,可训练(对话模板映射函数)
多数据样本拼接
实战:使用XTuner单卡微调属于自己的开源模型(以InternLM为基底)
环境安装
1 |
|
准备在 oasst1 数据集上微调 internlm-7b-chat
1 | # 创建一个微调 oasst1 数据集的工作路径,进入 |
微调
准备配置文件
XTuner 提供多个开箱即用的配置文件,用户可以通过下列命令查看:
1 | # 列出所有内置配置 |
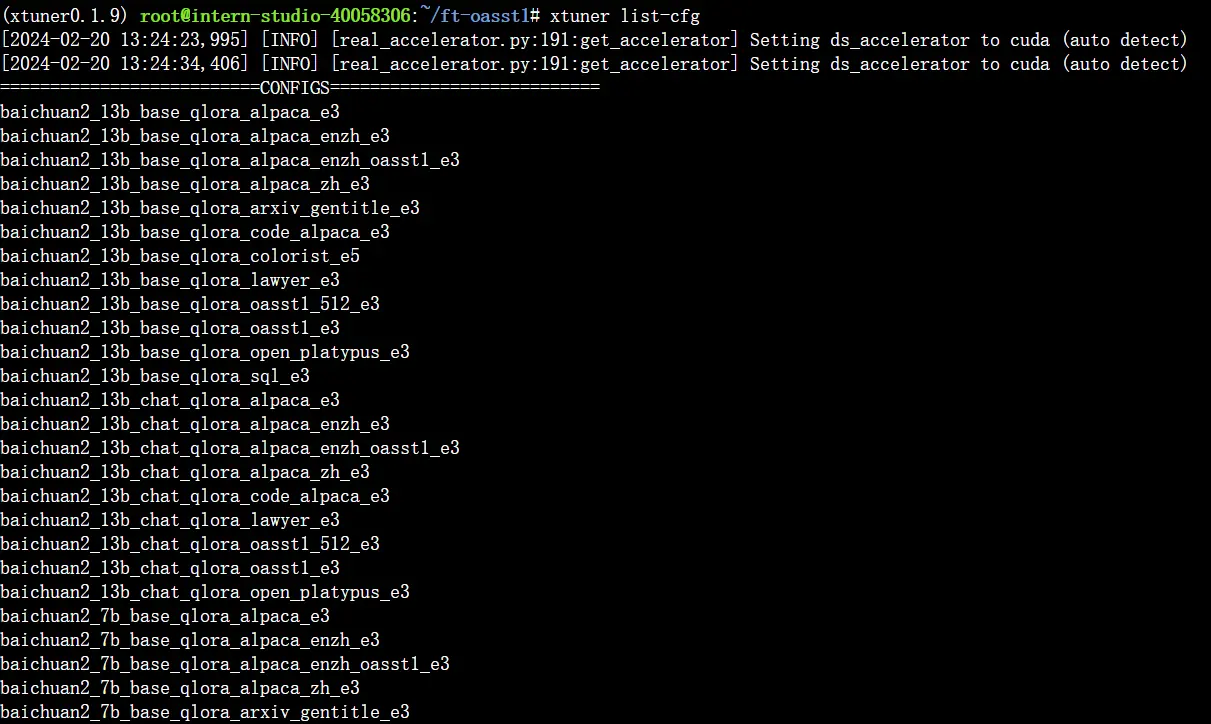
拷贝一个配置文件到当前目录:# xtuner copy-cfg ${CONFIG_NAME} ${SAVE_PATH}
在本案例中即:(注意最后有个英文句号,代表复制到当前路径)
1 | cd ~/ft-oasst1 |
配置文件名的解释:
xtuner copy-cfg internlm_chat_7b_qlora_oasst1_e3 .
| 模型名 | internlm_chat_7b |
|---|---|
| 使用算法 | qlora |
| 数据集 | oasst1 |
| 把数据集跑几次 | 跑3次:e3 (epoch 3 ) |
*无 chat比如 internlm-7b 代表是基座(base)模型
模型下载
1 | ln -s /share/temp/model_repos/internlm-chat-7b ~/ft-oasst1/ |
以上是通过软链的方式,将模型文件挂载到家目录下,优势是:
- 节省拷贝时间,无需等待
- 节省用户开发机存储空间
当然,也可以用
cp -r /share/temp/model_repos/internlm-chat-7b ~/ft-oasst1/进行数据拷贝。
数据集下载
数据集
为了推动大规模对齐研究的民主化,产生了OpenAssistant Conversations(OASST1)数据集,这是一个人工生成、人工注释的助手式对话语料库,包含161,443个消息,涵盖35种不同的语言,标注了461,292个质量评分,共有超过10,000个完全标注的对话树。
1 | cd ~/ft-oasst1 |
此时,当前路径的文件:
1 | . |
修改配置文件
修改其中的模型和数据集为 本地路径
1 | cd ~/ft-oasst1 |
减号代表要删除的行,加号代表要增加的行。
1 | # 修改模型为本地路径 |
常用超参
| 参数名 | 解释 |
|---|---|
| data_path | 数据路径或 HuggingFace 仓库名 |
| max_length | 单条数据最大 Token 数,超过则截断 |
| pack_to_max_length | 是否将多条短数据拼接到 max_length,提高 GPU 利用率 |
| accumulative_counts | 梯度累积,每多少次 backward 更新一次参数 |
| evaluation_inputs | 训练过程中,会根据给定的问题进行推理,便于观测训练状态 |
| evaluation_freq | Evaluation 的评测间隔 iter 数 |
| …… | …… |
如果想把显卡的现存吃满,充分利用显卡资源,可以将
max_length和batch_size这两个参数调大。
开始微调
训练:
1 | xtuner train ${CONFIG_NAME_OR_PATH} |
也可以增加 deepspeed 进行训练加速:
1 | xtuner train ${CONFIG_NAME_OR_PATH} --deepspeed deepspeed_zero2 |
例如,我们可以利用 QLoRA 算法在 oasst1 数据集上微调 InternLM-7B:
1 | # 单卡 |
微调得到的 PTH 模型文件和其他杂七杂八的文件都默认在当前的
./work_dirs中。
工具:tmux学习
1 | #更新源 |
跑完训练后,当前路径:
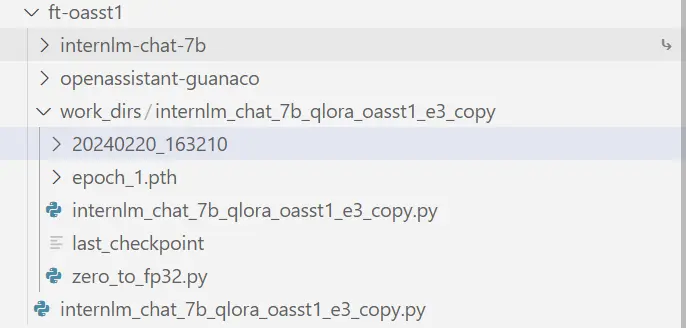
将得到的 PTH 模型转换为 HuggingFace 模型,即:生成 Adapter 文件夹
xtuner convert pth_to_hf ${CONFIG_NAME_OR_PATH} ${PTH_file_dir} ${SAVE_PATH}
在本示例中,为:
1 | mkdir hf |
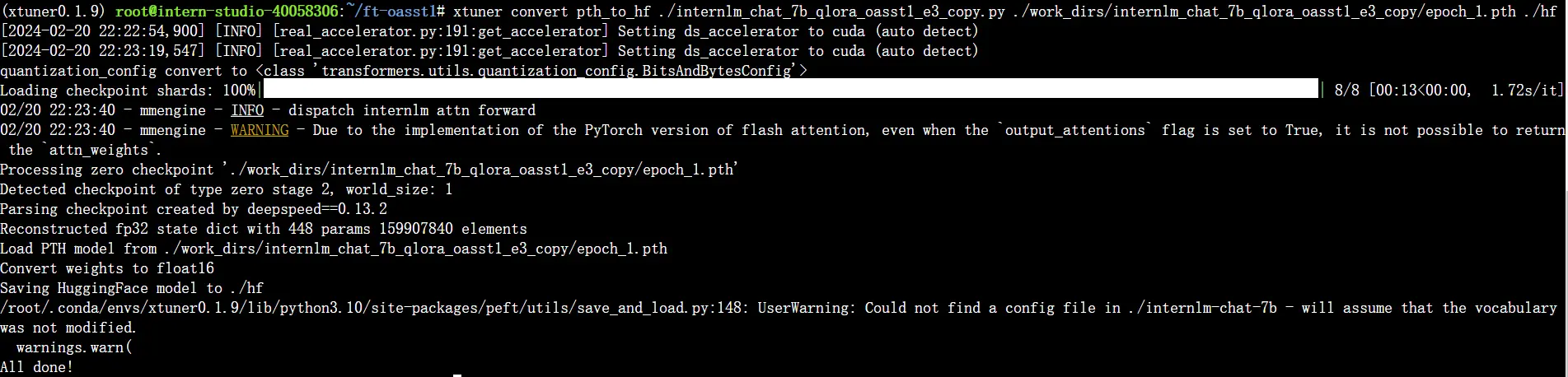
此时,路径中应该长这样:
1 | . |
此时,hf 文件夹即为我们平时所理解的所谓 “LoRA 模型文件”
可以简单理解:LoRA 模型文件 = Adapter
部署与测试
将 HuggingFace adapter 合并到大语言模型:
1 | xtuner convert merge ./internlm-chat-7b ./hf ./merged --max-shard-size 2GB |
与合并后的模型对话:
1 | # 加载 Adapter 模型对话(Float 16) |
xtuner chat 的启动参数
| 启动参数 | 干哈滴 |
|---|---|
| —prompt-template | 指定对话模板 |
| —system | 指定SYSTEM文本 |
| —system-template | 指定SYSTEM模板 |
| --bits | LLM位数 |
| —bot-name | bot名称 |
| —with-plugins | 指定要使用的插件 |
| —no-streamer | 是否启用流式传输 |
| —lagent | 是否使用lagent |
| —command-stop-word | 命令停止词 |
| —answer-stop-word | 回答停止词 |
| —offload-folder | 存放模型权重的文件夹(或者已经卸载模型权重的文件夹) |
| —max-new-tokens | 生成文本中允许的最大 token 数量 |
| —temperature | 温度值 |
| —top-k | 保留用于顶k筛选的最高概率词汇标记数 |
| —top-p | 如果设置为小于1的浮点数,仅保留概率相加高于 top_p 的最小一组最有可能的标记 |
| —seed | 用于可重现文本生成的随机种子 |
自定义微调
以 Medication QA 数据集为例
概述
场景需求
基于 InternLM-chat-7B 模型,用 MedQA 数据集进行微调,将其往医学问答领域对齐。
真实数据预览
| 问题 | 答案 |
|---|---|
| What are ketorolac eye drops?(什么是酮咯酸滴眼液?) | Ophthalmic ketorolac is used to treat itchy eyes caused by allergies. It also is used to treat swelling and redness (inflammation) that can occur after cataract surgery. Ketorolac is in a class of medications called nonsteroidal anti-inflammatory drugs (NSAIDs). It works by stopping the release of substances that cause allergy symptoms and inflammation. |
| What medicines raise blood sugar? (什么药物会升高血糖?) | Some medicines for conditions other than diabetes can raise your blood sugar level. This is a concern when you have diabetes. Make sure every doctor you see knows about all of the medicines, vitamins, or herbal supplements you take. This means anything you take with or without a prescription. Examples include: Barbiturates. Thiazide diuretics. Corticosteroids. Birth control pills (oral contraceptives) and progesterone. Catecholamines. Decongestants that contain beta-adrenergic agents, such as pseudoephedrine. The B vitamin niacin. The risk of high blood sugar from niacin lowers after you have taken it for a few months. The antipsychotic medicine olanzapine (Zyprexa). |
数据准备
以 Medication QA 数据集为例
原格式:(.xlsx)
https://github.com/InternLM/tutorial/blob/main/xtuner/MedQA2019.xlsx
| 问题 | 药物类型 | 问题类型 | 回答 | 主题 | URL |
|---|---|---|---|---|---|
| aaa | bbb | ccc | ddd | eee | fff |
将数据转为 XTuner 的数据格式
目标格式:(.jsonL)
1 | [{ |
🧠通过 python 脚本:将 .xlsx 中的 问题 和 回答 两列 提取出来,再放入 .jsonL 文件的每个 conversation 的 input 和 output 中。
这一步的 python 脚本可以请 ChatGPT 来完成。
1 | Write a python file for me. using openpyxl. input file name is MedQA2019.xlsx |
ChatGPT 生成的 python 代码见xlsx2jsonl.py
执行 python 脚本,获得格式化后的数据集:
1 | python xlsx2jsonl.py |
此时,当然也可以对数据进行训练集和测试集的分割,同样可以让 ChatGPT 写 python 代码。当然如果没有严格的科研需求、不在乎“训练集泄露”的问题,也可以不做训练集与测试集的分割。
划分训练集和测试集
1 | my .jsonL file looks like: |
生成的python代码见 split2train_and_test.py
开始自定义微调
此时,我们重新建一个文件夹来玩“微调自定义数据集”
1 | mkdir ~/ft-medqa && cd ~/ft-medqa |
把前面下载好的internlm-chat-7b模型文件夹拷贝过来。
1 | cp -r ~/ft-oasst1/internlm-chat-7b . |
别忘了把自定义数据集,即几个 .jsonL,也传到服务器上。
1 | git clone https://github.com/InternLM/tutorial |
1 | cp ~/tutorial/xtuner/MedQA2019-structured-train.jsonl . |
准备配置文件
1 | # 复制配置文件到当前目录 |
减号代表要删除的行,加号代表要增加的行。
1 | # 修改import部分 |
3.3.2 XTuner!启动!
1 | xtuner train internlm_chat_7b_qlora_medqa2019_e3.py --deepspeed deepspeed_zero2 |
3.3.3 pth 转 huggingface
同前述,这里不赘述了。
3.3.4 部署与测试
同前述。
4【补充】用 MS-Agent 数据集 赋予 LLM 以 Agent 能力
4.1 概述
MSAgent 数据集每条样本包含一个对话列表(conversations),其里面包含了 system、user、assistant 三种字段。其中:
system: 表示给模型前置的人设输入,其中有告诉模型如何调用插件以及生成请求
user: 表示用户的输入 prompt,分为两种,通用生成的prompt和调用插件需求的 prompt
assistant: 为模型的回复。其中会包括插件调用代码和执行代码,调用代码是要 LLM 生成的,而执行代码是调用服务来生成结果的
一条调用网页搜索插件查询“上海明天天气”的数据样本示例。
4.2.1 准备工作
xtuner 是从国内的 ModelScope 平台下载 MS-Agent 数据集,因此不用提前手动下载数据集文件。
1 | # 准备工作 |
1 | - pretrained_model_name_or_path = 'internlm/internlm-chat-7b' |
4.2.2 开始微调
1 | xtuner train ./internlm_7b_qlora_msagent_react_e3_gpu8_copy.py --deepspeed deepspeed_zero2 |
4.3 直接使用
由于 msagent 的训练非常费时,大家如果想尽快把这个教程跟完,可以直接从 modelScope 拉取咱们已经微调好了的 Adapter。如下演示。
4.3.1 下载 Adapter
1 | cd ~/ft-msagent |
OK,现在目录应该长这样:
- internlm_7b_qlora_msagent_react_e3_gpu8_copy.py
- internlm-7b-qlora-msagent-react
- internlm-chat-7b
- work_dir(可有可无)
有了这个在 msagent 上训练得到的Adapter,模型现在已经有 agent 能力了!就可以加 —lagent 以调用来自 lagent 的代理功能了!
4.3.2 添加 serper 环境变量
开始 chat 之前,还要加个 serper 的环境变量:
去 serper.dev 免费注册一个账号,生成自己的 api key。这个东西是用来给 lagent 去获取 google 搜索的结果的。等于是 serper.dev 帮你去访问 google,而不是从你自己本地去访问 google 了。
添加 serper api key 到环境变量:
1 | export SERPER_API_KEY=abcdefg |
4.3.3 xtuner + agent,启动!
1 | xtuner chat ./internlm-chat-7b --adapter internlm-7b-qlora-msagent-react --lagent |
参考
https://github.com/InternLM/tutorial/blob/main/xtuner/README.md
https://broadleaf-gemini-274.notion.site/Lecture4-XTuner-d6399774b18f4818ba8eeb1eceaf7a08