10 | 闭包: 理解了原理,它就不反直觉了





讲述:宫文学
时长14:31大小13.30M
在讲作用域和生存期时,我提到函数里的本地变量只能在函数内部访问,函数退出之后,作用域就没用了,它对应的栈桢被弹出,作用域中的所有变量所占用的内存也会被收回。
但偏偏跑出来闭包(Closure)这个怪物。
在 JavaScript 中,用外层函数返回一个内层函数之后,这个内层函数能一直访问外层函数中的本地变量。按理说,这个时候外层函数已经退出了,它里面的变量也该作废了。可闭包却非常执着,即使外层函数已经退出,但内层函数仿佛不知道这个事实一样,还继续访问外层函数中声明的变量,并且还真的能够正常访问。
不过,闭包是很有用的,对库的编写者来讲,它能隐藏内部实现细节;对面试者来讲,它几乎是前端面试必问的一个问题,比如如何用闭包特性实现面向对象编程?等等。
本节课,我会带你研究闭包的实现机制,让你深入理解作用域和生存期,更好地使用闭包特性。为此,要解决两个问题:
- 函数要变成 playscript 的一等公民。也就是要能把函数像普通数值一样赋值给变量,可以作为参数传递给其他函数,可以作为函数的返回值。
- 要让内层函数一直访问它环境中的变量,不管外层函数退出与否。
我们先通过一个例子,研究一下闭包的特性,看看它另类在哪里。
闭包的内在矛盾
来测试一下 JavaScript 的闭包特性:
在 Node.js 环境下运行上面这段代码的结果如下:
观察这个结果,可以得出两点:
- 内层的函数能访问它“看得见”的变量,包括自己的本地变量、外层函数的变量 b 和全局变量 a。
- 内层函数作为返回值赋值给其他变量以后,外层函数就结束了,但内层函数仍能访问原来外层函数的变量 b,也能访问全局变量 a。
这样似乎让人感到困惑:站在外层函数的角度看,明明这个函数已经退出了,变量 b 应该失效了,为什么还可以继续访问?但是如果换个立场,站在 inner 这个函数的角度来看,声明 inner 函数的时候,告诉它可以访问 b,不能因为把 inner 函数赋值给了其他变量,inner 函数里原本正确的语句就不能用了啊。
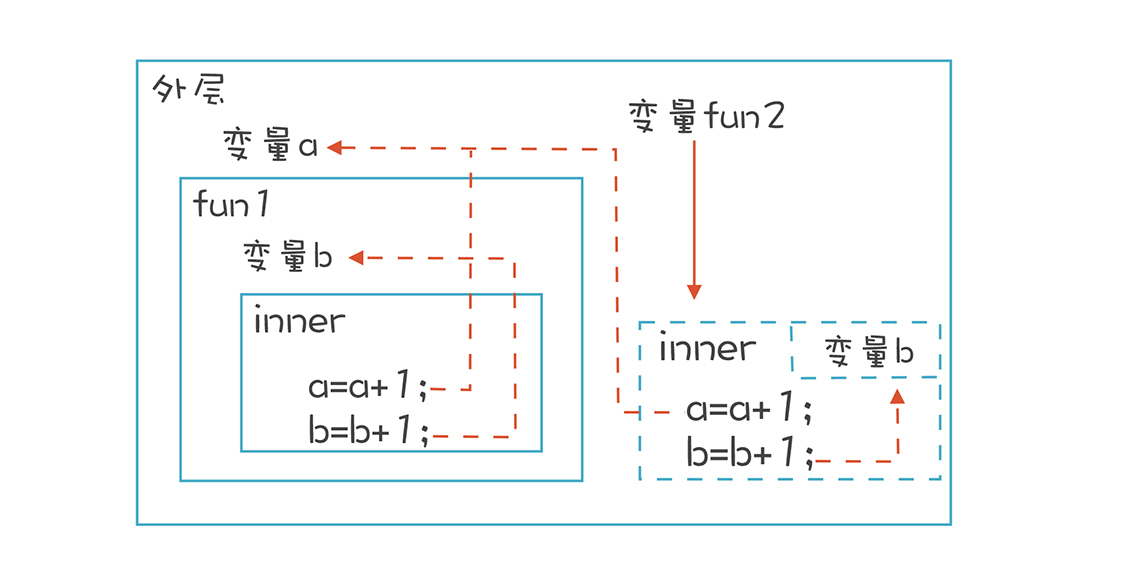
其实,只要函数能作为值传来传去,就一定会产生作用域不匹配的情况,这样的内在矛盾是语言设计时就决定了的。我认为,闭包是为了让函数能够在这种情况下继续运行所提供的一个方案。这个方案有一些不错的特点,比如隐藏函数所使用的数据,歪打正着反倒成了一个优点了!
在这里,我想补充一下静态作用域(Static Scope)这个知识点,如果一门语言的作用域是静态作用域,那么符号之间的引用关系能够根据程序代码在编译时就确定清楚,在运行时不会变。某个函数是在哪声明的,就具有它所在位置的作用域。它能够访问哪些变量,那么就跟这些变量绑定了,在运行时就一直能访问这些变量。
看一看下面的代码,对于静态作用域而言,无论在哪里调用 foo() 函数,访问的变量 i 都是全局变量:
我们目前使用的大多数语言都是采用静态作用域的。playscript 语言也是在编译时就形成一个 Scope 的树,变量的引用也是在编译时就做了消解,不再改变,所以也是采用了静态作用域。
反过来讲,如果在 bar() 里调用 foo() 时,foo() 访问的是 bar() 函数中的本地变量 i,那就说明这门语言使用的是动态作用域(Dynamic Scope)。也就是说,变量引用跟变量声明不是在编译时就绑定死了的。在运行时,它是在运行环境中动态地找一个相同名称的变量。在 macOS 或 Linux 中用的 bash 脚本语言,就是动态作用域的。
静态作用域可以由程序代码决定,在编译时就能完全确定,所以又叫做词法作用域(Lexcical Scope)。不过这个词法跟我们做词法分析时说的词法不大一样。这里,跟 Lexical 相对应的词汇可以认为是 Runtime,一个是编写时,一个是运行时。
用静态作用域的概念描述一下闭包,我们可以这样说:因为我们的语言是静态作用域的,它能够访问的变量,需要一直都能访问,为此,需要把某些变量的生存期延长。
当然了,闭包的产生还有另一个条件,就是让函数成为一等公民。这是什么意思?我们又怎样实现呢?
函数作为一等公民
在 JavaScript 和 Python 等语言里,函数可以像数值一样使用,比如给变量赋值、作为参数传递给其他函数,作为函数返回值等等。这时,我们就说函数是一等公民。
作为一等公民的函数很有用,比如它能处理数组等集合。我们给数组的 map 方法传入一个回调函数,结果会生成一个新的数组。整个过程很简洁,没有出现啰嗦的循环语句,这也是很多人提倡函数式编程的原因之一:
那么在 playscript 中,怎么把函数作为一等公民呢?
我们需要支持函数作为基础类型,这样就可以用这种类型声明变量。但问题来了,如何声明一个函数类型的变量呢?
在 JavaScript 这种动态类型的语言里,我们可以把函数赋值给任何一个变量,就像前面示例代码里的那样:inner 函数作为返回值,被赋给了 fun2 和 fun3 两个变量。
然而在 Go 语言这样要求严格类型匹配的语言里,就比较复杂了:
它对函数的原型有比较严格的要求:函数必须有一个 int 型的参数,返回值也必须是 int 型的。
而 C 语言中函数指针的声明也是比较严格的,在下面的代码中,myFun 指针能够指向一个函数,这个函数也是有一个 int 类型的参数,返回值也是 int:
playscript 也采用这种比较严格的声明方式,因为我们想实现一个静态类型的语言:
写成上面这样是因为我个人喜欢把变量名称左边的部分看做类型的描述,不像 Go 语言把类型放在变量名称后面。最难读的就是 C 语言那种声明方式了,竟然把变量名放在了中间。当然,这只是个人喜好。
把上面描述函数类型的语法写成 Antlr 的规则如下:
在 playscript 中,我们用 FuntionType 接口代表一个函数类型,通过这个接口可以获得返回值类型、参数类型这两个信息:
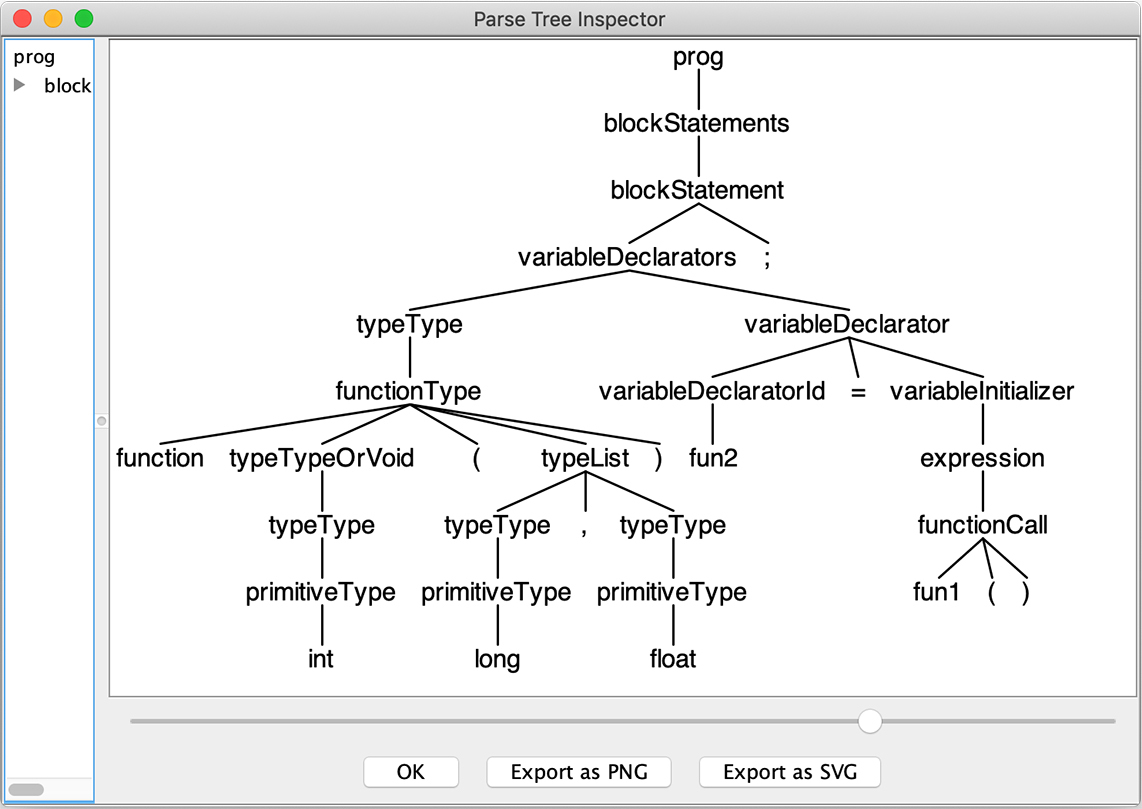
试一下实际使用效果如何,用 Antlr 解析下面这句的语法:
它的意思是:调用 fun1() 函数会返回另一个函数,这个函数有两个参数,返回值是 int 型的。
我们用 grun 显示一下 AST,你可以看到,它已经把 functionType 正确地解析出来了:
目前,我们只是设计完了语法,还要实现运行期的功能,让函数真的能像数值一样传来传去,就像下面的测试代码,它把 foo() 作为值赋给了 bar():
运行结果如下:
运行这段代码,你会发现它实现了用函数来赋值,而实现这个功能的重点,是做好语义分析。比如编译程序要能识别赋值语句中的 foo 是一个函数,而不是一个传统的值。在调用 a() 和 b() 的时候,它也要正确地调用 foo() 的代码,而不是报“找不到 a() 函数的定义”这样的错误。
实现了一等公民函数的功能以后,我们进入本讲最重要的一环:实现闭包功能。
实现我们自己的闭包机制
在这之前,我想先设计好测试用例,所以先把一开始提到的那个 JavaScript 的例子用 playscript 的语法重写一遍,来测试闭包功能:
代码的运行效果跟 JavaScript 版本的程序是一样的:
这段代码的 AST 我也让 grun 显示出来了,并截了一部分图,你可以直观地看一下外层函数和内层函数的关系:
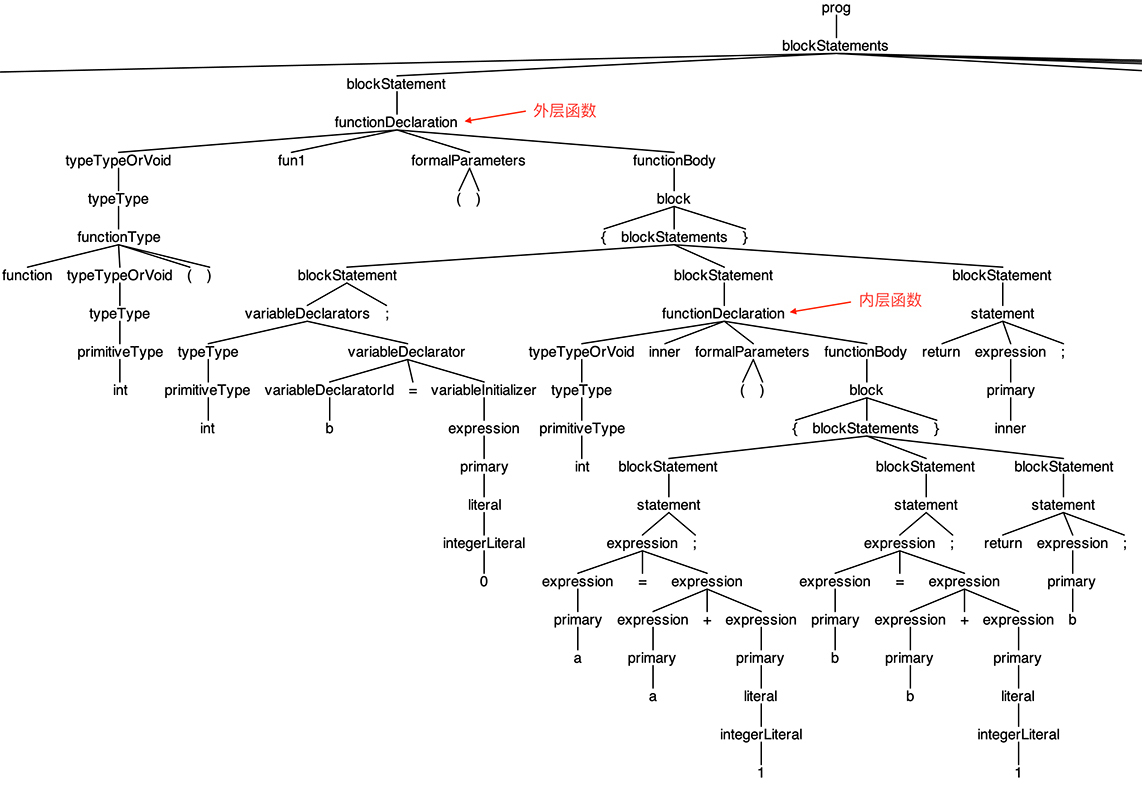
现在,测试用例准备好了,我们着手实现一下闭包的机制。
前面提到,闭包的内在矛盾是运行时的环境和定义时的作用域之间的矛盾。那么我们把内部环境中需要的变量,打包交给闭包函数,它就可以随时访问这些变量了。
在 AST 上做一下图形化的分析,看看给 fun2 这个变量赋值的时候,发生了什么事情:
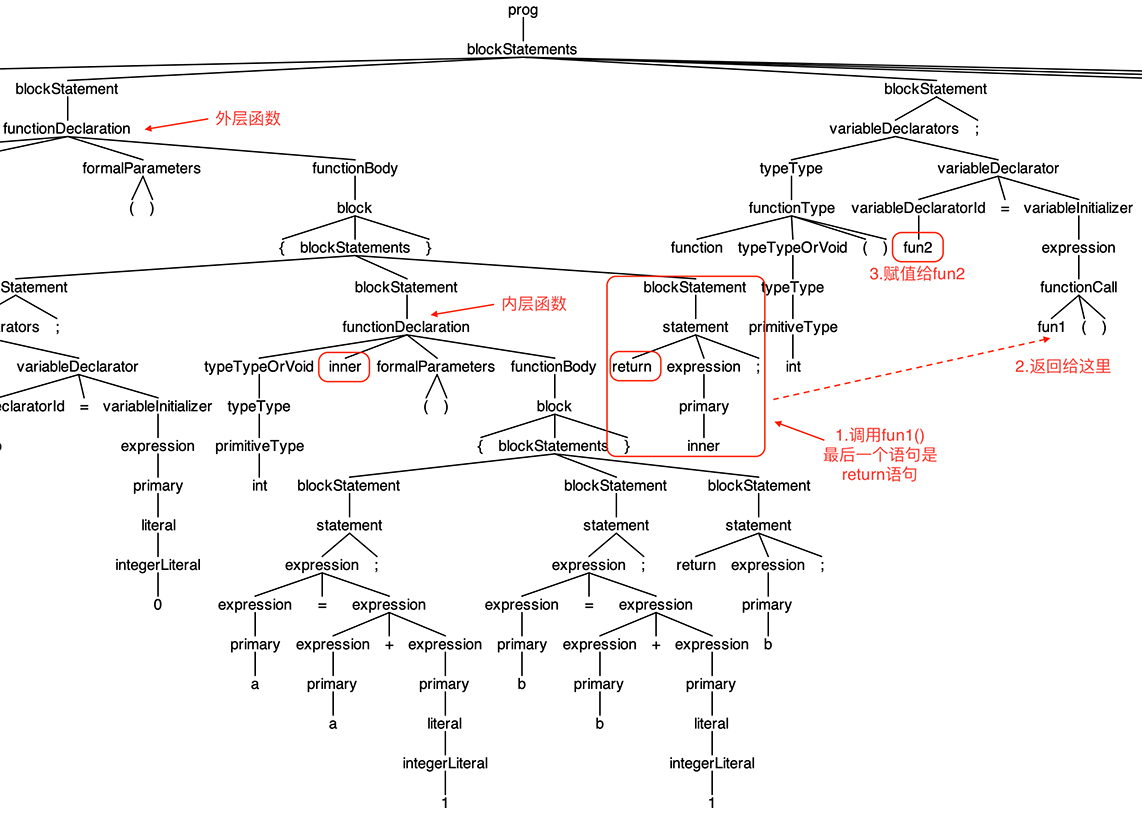
简单地描述一下给 fun2 赋值时的执行过程:
-
先执行 fun1() 函数,内部的 inner() 函数作为返回值返回给调用者。这时,程序能访问两层作用域,最近一层是 fun1(),里面有变量 b;外层还有一层,里面有全局变量 a。这时是把环境变量打包的最后的机会,否则退出 fun1() 函数以后,变量 b 就消失了。
-
然后把内部函数连同打包好的环境变量的值,创建一个 FunctionObject 对象,作为 fun1() 的返回值,给到调用者。
-
给 fun2 这个变量赋值。
-
调用 fun2() 函数。函数执行时,有一个私有的闭包环境可以访问 b 的值,这个环境就是第二步所创建的 FunctionObject 对象。
最终,我们实现了闭包的功能。
在这个过程中,我们要提前记录下 inner() 函数都引用了哪些外部变量,以便对这些变量打包。这是在对程序做语义分析时完成的,你可以参考一下 ClosureAnalyzer.java 中的代码:
下面是 ASTEvaluator.java 中把环境变量打包进闭包中的代码片段,它是在当前的栈里获取数据的:
你可以把测试用例跑一跑,修改一下,试试其他闭包特性。
体验一下函数式编程
现在,我们已经实现了闭包的机制,函数也变成了一等公民。不经意间,我们似乎在一定程度上支持了函数式编程(functional programming)。
它是一种语言风格,有很多优点,比如简洁、安全等。备受很多程序员推崇的 LISP 语言就具备函数式编程特征,Java 等语言也增加了函数式编程的特点。
函数式编程的一个典型特点就是高阶函数(High-order function)功能,高阶函数是这样一种函数,它能够接受其他函数作为自己的参数,javascript 中数组的 map 方法,就是一个高阶函数。我们通过下面的例子测试一下高阶函数功能:
运行后得到的结果如下:
高阶函数功能很好玩,你可以修改程序,好好玩一下。
课程小结
闭包这个概念,对于初学者来讲是一个挑战。其实,闭包就是把函数在静态作用域中所访问的变量的生存期拉长,形成一份可以由这个函数单独访问的数据。正因为这些数据只能被闭包函数访问,所以也就具备了对信息进行封装、隐藏内部细节的特性。
听上去是不是有点儿耳熟?封装,把数据和对数据的操作封在一起,这不就是面向对象编程嘛!一个闭包可以看做是一个对象。反过来看,一个对象是不是也可以看做一个闭包呢?对象的属性,也可以看做被方法所独占的环境变量,其生存期也必须保证能够被方法一直正常的访问。
你看,两个不相干的概念,在用作用域和生存期这样的话语体系去解读之后,就会很相似,在内部实现上也可以当成一回事。现在,你应该更清楚了吧?
一课一思
思考一下我在开头提到的那个面试题:如何用闭包做类似面向对象的编程?
其实,我在课程中提供了一个 closure-mammal.play 的示例代码,它完全用闭包的概念实现了面向对象编程的多态特征。而这个闭包的实现,是一种更高级的闭包,比普通的函数闭包还多了一点有用的特性,更像对象了。我希望你能发现它到底不同在哪里,也能在代码中找到实现这些特性的位置。
你能发现,我一直在讲作用域和生存期,不要嫌我啰嗦,把它们吃透,会对你使用语言有很大帮助。比如,有同学非常困扰 JavaScript 的 this,我负责任地讲,只要对作用域有清晰的了解,你就能很容易地掌握 this。
那么,关于作用域跟 this 之间的关联,如果你有什么想法,也欢迎在留言区分享。
最后,感谢你的阅读,如果这篇文章让你有所收获,也欢迎你将它分享给更多的朋友,特别是分享给那些还没搞清楚闭包的朋友。
本节课的示例代码放在了文末,供你参考。
- playscript-java(项目目录): 码云 GitHub
- PlayScript.java(入口程序): 码云 GitHub
- PlayScript.g4(语法规则): 码云 GitHub
- ASTEvaluator.java(解释器,找找闭包运行期时怎么实现的): 码云 GitHub
- ClosureAnalyzer.java(分析闭包所引用的环境变量):码云 GitHub
- RefResolver.java(在这里看看函数型变量是怎么消解的): 码云 GitHub
- closure.play(演示基本的闭包特征): 码云 GitHub
- closure-fibonacci.play(用闭包实现了斐波那契数列计算):码云 GitHub
- closure-mammal.play(用闭包实现了面向对象特性,请找找它比普通闭包强在哪里):码云 GitHub
- FirstClassFunction.play(演示一等公民函数的特征):码云 GitHub
- LinkedList.play(演示了高阶函数 map):码云 GitHub

精选留言(5)
 沉淀的梦想2019-09-07/*
沉淀的梦想2019-09-07/*
这是针对函数可能是一等公民的情况。这个时候,函数运行时的作用域,与声明时的作用域会不一致。
我在这里设计了一个“receiver”的机制,意思是这个函数是被哪个变量接收了。要按照这个receiver的作用域来判断。
*/
else if (frame.object instanceof FunctionObject){
FunctionObject functionObject = (FunctionObject)frame.object;
if (functionObject.receiver != null && functionObject.receiver.enclosingScope == f.scope) {
frame.parentFrame = f;
break;
}
}
不是很理解老师的这个receiver机制,能举个例子吗?展开 SUNFEI2019-09-07精彩。展开
SUNFEI2019-09-07精彩。展开 Geek_d0aef12019-09-06想问个没有技术含量的问题,想确认下,antlr 自动生成的代码只有4个,其他都是自己手动写的?
Geek_d0aef12019-09-06想问个没有技术含量的问题,想确认下,antlr 自动生成的代码只有4个,其他都是自己手动写的?- 沉淀的梦想2019-09-06闭包如果引用的是外部函数中的局部变量,直接把这个变量从栈中复制一份到FunctionObject里面就可以了,但是如果应用了全局变量的话,感觉必须要引用全局变量本身,这样才能自己的修改体现在全局变量中。老师代码中是如何实现这个的呢?展开 1
 茶底2019-09-05老师什么时候开始讲lex和yacc啊展开
茶底2019-09-05老师什么时候开始讲lex和yacc啊展开作者回复: lex和yacc都没计划讲。因为这些工具都差不多。掌握原理后,用哪个应该都没问题。
lex(或flex)比较简单,所以会用Antlr一定也会用lex。
yacc(或bison)是LR算法的,我们讲完LR算法以后,你理解这个工具的原理应该也没啥问题。


