08 | 作用域和生存期:实现块作用域和函数





讲述:宫文学
时长13:36大小12.46M
目前,我们已经用 Antlr 重构了脚本解释器,有了工具的帮助,我们可以实现更高级的功能,比如函数功能、面向对象功能。当然了,在这个过程中,我们还要克服一些挑战,比如:
- 如果要实现函数功能,要升级变量管理机制;
- 引入作用域机制,来保证变量的引用指向正确的变量定义;
- 提升变量存储机制,不能只把变量和它的值简单地扔到一个 HashMap 里,要管理它的生存期,减少对内存的占用。
本节课,我将借实现块作用域和函数功能,带你探讨作用域和生存期及其实现机制,并升级变量管理机制。那么什么是作用域和生存期,它们的重要性又体现在哪儿呢?
“作用域”和“生存期”是计算机语言中更加基础的概念,它们可以帮你深入地理解函数、块、闭包、面向对象、静态成员、本地变量和全局变量等概念。
而且一旦你深入理解,了解作用域与生存期在编译期和运行期的机制之后,就能解决在学习过程中可能遇到的一些问题,比如:
- 闭包的机理到底是什么?
- 为什么需要栈和堆两种机制来管理内存?它们的区别又是什么?
- 一个静态的内部类和普通的内部类有什么区别?
了解上面这些内容之后,接下来,我们来具体看看什么是作用域。
作用域(Scope)
作用域是指计算机语言中变量、函数、类等起作用的范围,我们来看一个具体的例子。
下面这段代码是用 C 语言写的,我们在全局以及函数 fun 中分别声明了 a 和 b 两个变量,然后在代码里对这些变量做了赋值操作:
这段代码编译后运行,结果是:
我们可以得出这样的规律:
- 变量的作用域有大有小,外部变量在函数内可以访问,而函数中的本地变量,只有本地才可以访问。
- 变量的作用域,从声明以后开始。
- 在函数里,我们可以声明跟外部变量相同名称的变量,这个时候就覆盖了外部变量。
下面这张图直观地显示了示例代码中各个变量的作用域:
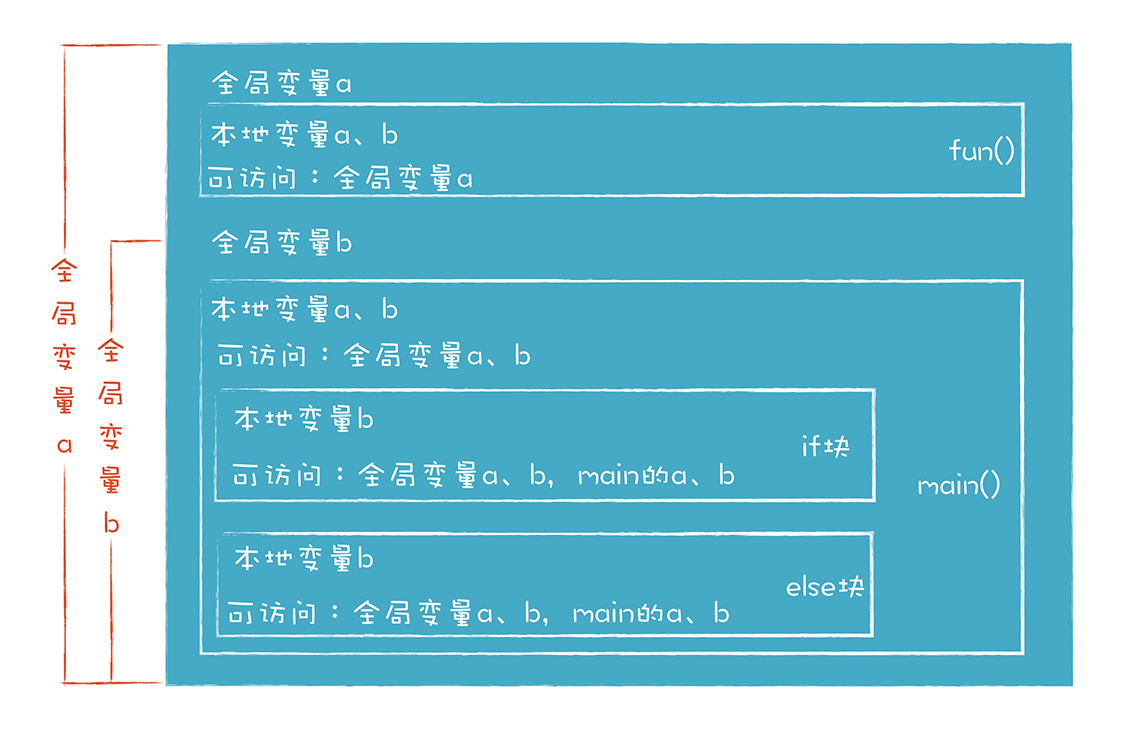
另外,C 语言里还有块作用域的概念,就是用花括号包围的语句,if 和 else 后面就跟着这样的语句块。块作用域的特征跟函数作用域的特征相似,都可以访问外部变量,也可以用本地变量覆盖掉外部变量。
你可能会问:“其他语言也有块作用域吗?特征是一样的吗?”其实,各个语言在这方面的设计机制是不同的。比如,下面这段用 Java 写的代码里,我们用了一个 if 语句块,并且在 if 部分、else 部分和外部分别声明了一个变量 c:
你能看到,Java 的块作用域跟 C 语言的块作用域是不同的,它不允许块作用域里的变量覆盖外部变量。那么和 C、Java 写起来很像的 JavaScript 呢?来看一看下面这段测试 JavaScript 作用域的代码:
这段代码编译后运行,结果是:
你可以看到,JavaScript 是没有块作用域的。我们在块里和 for 语句试图重新定义变量 b,语法上是允许的,但我们每次用到的其实是同一个变量。
对比了三种语言的作用域特征之后,你是否发现原来看上去差不多的语法,内部机理却不同?这种不同其实是语义差别的一个例子。你要注意的是,现在我们讲的很多内容都已经属于语义的范畴了,对作用域的分析就是语义分析的任务之一。
生存期(Extent)
了解了什么是作用域之后,我们再理解一下跟它紧密相关的生存期。它是变量可以访问的时间段,也就是从分配内存给它,到收回它的内存之间的时间。
在前面几个示例程序中,变量的生存期跟作用域是一致的。出了作用域,生存期也就结束了,变量所占用的内存也就被释放了。这是本地变量的标准特征,这些本地变量是用栈来管理的。
但也有一些情况,变量的生存期跟语法上的作用域不一致,比如在堆中申请的内存,退出作用域以后仍然会存在。
下面这段 C 语言的示例代码中,fun 函数返回了一个整数的指针。出了函数以后,本地变量 b 就消失了,这个指针所占用的内存(&b)就收回了,其中 &b 是取 b 的地址,这个地址是指向栈里的一小块空间,因为 b 是栈里申请的。在这个栈里的小空间里保存了一个地址,指向在堆里申请的内存。这块内存,也就是用来实际保存数值 2 的空间,并没有被收回,我们必须手动使用 free() 函数来收回。
类似的情况在 Java 里也有。Java 的对象实例缺省情况下是在堆中生成的。下面的示例代码中,从一个方法中返回了对象的引用,我们可以基于这个引用继续修改对象的内容,这证明这个对象的内存并没有被释放:
因为 Java 对象所采用的内存超出了申请内存时所在的作用域,所以也就没有办法自动收回。所以 Java 采用的是自动内存管理机制,也就是垃圾回收技术。
那么为什么说作用域和生存期是计算机语言更加基础的概念呢?其实是因为它们对应到了运行时的内存管理的基本机制。虽然各门语言设计上的特性是不同的,但在运行期的机制都很相似,比如都会用到栈和堆来做内存管理。
好了,理解了作用域和生存期的原理之后,我们就来实现一下,先来设计一下作用域机制,然后再模拟实现一个栈。
实现作用域和栈
在之前的 PlayScript 脚本的实现中,处理变量赋值的时候,我们简单地把变量存在一个哈希表里,用变量名去引用,就像下面这样:
但如果变量存在多个作用域,这样做就不行了。这时,我们就要设计一个数据结构,区分不同变量的作用域。分析前面的代码,你可以看到作用域是一个树状的结构,比如 Scope.c 的作用域:
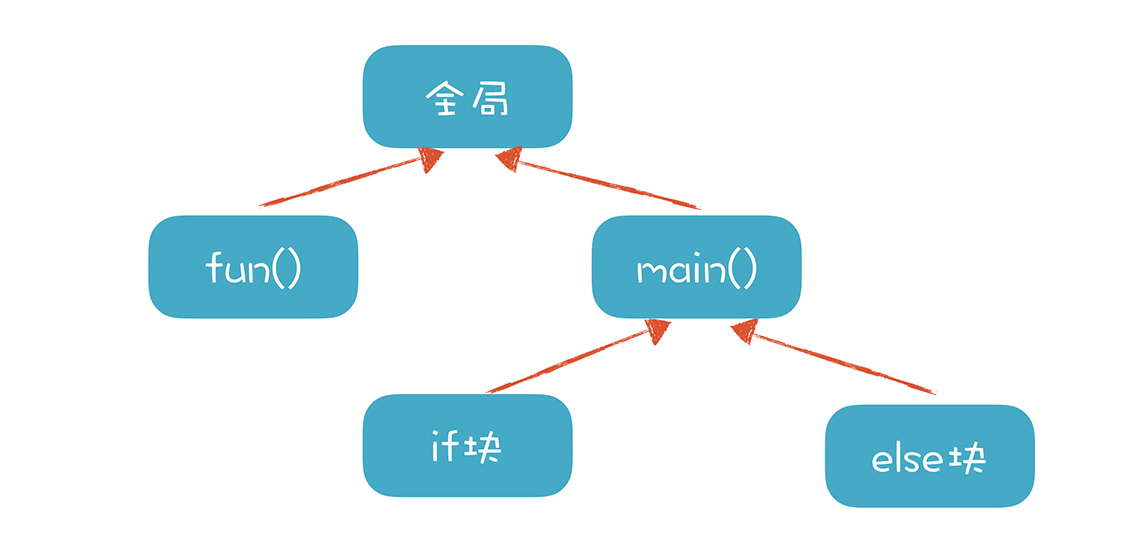
面向对象的语言不太相同,它不是一棵树,是一片树林,每个类对应一棵树,所以它也没有全局变量。在我们的 playscript 语言中,我们设计了下面的对象结构来表示 Scope:
目前我们划分了三种作用域,分别是块作用域(Block)、函数作用域(Function)和类作用域(Class)。
我们在解释执行 playscript 的 AST 的时候,需要建立起作用域的树结构,对作用域的分析过程是语义分析的一部分。也就是说,并不是有了 AST,我们马上就可以运行它,在运行之前,我们还要做语义分析,比如对作用域做分析,让每个变量都能做正确的引用,这样才能正确地执行这个程序。
解决了作用域的问题以后,再来看看如何解决生存期的问题。还是看 Scope.c 的代码,随着代码的执行,各个变量的生存期表现如下:
- 进入程序,全局变量逐一生效;
- 进入 main 函数,main 函数里的变量顺序生效;
- 进入 fun 函数,fun 函数里的变量顺序生效;
- 退出 fun 函数,fun 函数里的变量失效;
- 进入 if 语句块,if 语句块里的变量顺序生效;
- 退出 if 语句块,if 语句块里的变量失效;
- 退出 main 函数,main 函数里的变量失效;
- 退出程序,全局变量失效。
通过下面这张图,你能直观地看到运行过程中栈的变化:
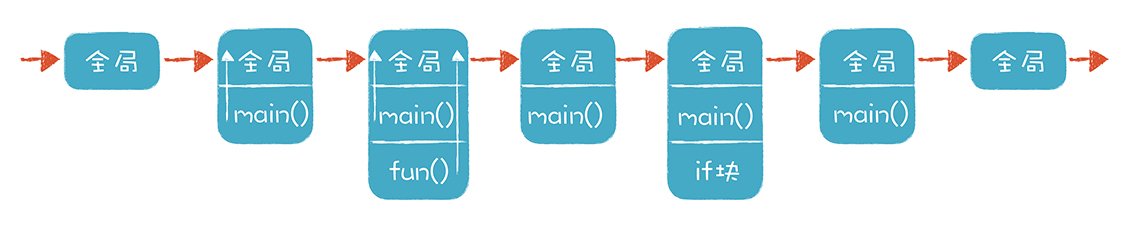
代码执行时进入和退出一个个作用域的过程,可以用栈来实现。每进入一个作用域,就往栈里压入一个数据结构,这个数据结构叫做栈桢(Stack Frame)。栈桢能够保存当前作用域的所有本地变量的值,当退出这个作用域的时候,这个栈桢就被弹出,里面的变量也就失效了。
你可以看到,栈的机制能够有效地使用内存,变量超出作用域的时候,就没有用了,就可以从内存中丢弃。我在 ASTEvaluator.java 中,用下面的数据结构来表示栈和栈桢,其中的 PlayObject 通过一个 HashMap 来保存各个变量的值:
目前,我们只是在概念上模仿栈桢,当我们用 Java 语言实现的时候,PlayObject 对象是存放在堆里的,Java 的所有对象都是存放在堆里的,只有基础数据类型,比如 int 和对象引用是放在栈里的。虽然只是模仿,这不妨碍我们建立栈桢的概念,在后端技术部分,我们会实现真正意义上的栈桢。
要注意的是,栈的结构和 Scope 的树状结构是不一致的。也就是说,栈里的上一级栈桢,不一定是 Scope 的父节点。要访问上一级 Scope 中的变量数据,要顺着栈桢的 parentFrame 去找。我在上图中展现了这种情况,在调用 fun 函数的时候,栈里一共有三个栈桢:全局栈桢、main() 函数栈桢和 fun() 函数栈桢,其中 main() 函数栈桢的 parentFrame 和 fun() 函数栈桢的 parentFrame 都是全局栈桢。
实现块作用域
目前,我们已经做好了作用域和栈,在这之后,就能实现很多功能了,比如让 if 语句和 for 循环语句使用块作用域和本地变量。以 for 语句为例,visit 方法里首先为它生成一个栈桢,并加入到栈中,运行完毕之后,再从栈里弹出:
当我们在代码中需要获取某个变量的值的时候,首先在当前桢中寻找。找不到的话,就到上一级作用域对应的桢中去找:
运行下面的测试代码,你会看到在执行完 for 循环以后,我们仍然可以声明另一个变量 i,跟 for 循环中的 i 互不影响,这证明它们确实属于不同的作用域:
进一步的,我们可以实现对函数的支持。
实现函数功能
先来看一下与函数有关的语法:
在函数里,我们还要考虑一个额外的因素:参数。在函数内部,参数变量跟普通的本地变量在使用时没什么不同,在运行期,它们也像本地变量一样,保存在栈桢里。
我们设计一个对象来代表函数的定义,它包括参数列表和返回值的类型:
在调用函数时,我们实际上做了三步工作:
- 建立一个栈桢;
- 计算所有参数的值,并放入栈桢;
- 执行函数声明中的函数体。
我把相关代码放在了下面,你可以看一下:
你可以用 playscript 测试一下函数执行的效果,看看参数传递和作用域的效果:
课程小结
本节课,我带你实现了块作用域和函数,还跟你一起探究了计算机语言的两个底层概念:作用域和生存期。你要知道:
- 对作用域的分析是语义分析的一项工作。Antlr 能够完成很多词法分析和语法分析的工作,但语义分析工作需要我们自己做。
- 变量的生存期涉及运行期的内存管理,也引出了栈桢和堆的概念,我会在编译器后端技术时进一步阐述。
我建议你在学习新语言的时候,先了解它在作用域和生存期上的特点,然后像示例程序那样做几个例子,借此你会更快理解语言的设计思想。比如,为什么需要命名空间这个特性?全局变量可能带来什么问题?类的静态成员与普通成员有什么区别?等等。
下一讲,我们会尝试实现面向对象特性,看看面向对象语言在语义上是怎么设计的,以及在运行期有什么特点。
一课一思
既然我强调了作用域和生存期的重要性,那么在你熟悉的语言中,有哪些特性是能用作用域和生存期的概念做更基础的解读呢?比如,面向对象的语言中,对象成员的作用域和生存期是怎样的?欢迎在留言区与大家一起交流。
最后,感谢你的阅读,如果这篇文章让你有所收获,也欢迎你将它分享给更多的朋友。
今天讲的功能照样能在 playscript-java 项目中找到示例代码,其中还有用 playscript 写的脚本,你可以多玩一玩。
- playscript-java(项目目录): 码云 GitHub
- PlayScript.java(入口程序):码云 GitHub
- PlayScript.g4(语法规则):码云 GitHub
- ASTEvaluator.java(解释器):码云 GitHub
- BlockScope.play(演示块作用域):码云 GitHub
- function.play(演示基础函数功能):码云 GitHub
- lab/scope 目录(各种语言的作用域测试):码云 GitHub

精选留言(7)
 Johnson2019-08-30现在课程的做法相当于AST之后直接解析执行了,所有的逻辑都堆在AST和紧接着的语义分析,没有把AST转化成IR,然后在这个IR上做各种事情,最后再到interpreter执行。是因为前期为了简单起见,所以先这么直观的来么?展开
Johnson2019-08-30现在课程的做法相当于AST之后直接解析执行了,所有的逻辑都堆在AST和紧接着的语义分析,没有把AST转化成IR,然后在这个IR上做各种事情,最后再到interpreter执行。是因为前期为了简单起见,所以先这么直观的来么?展开作者回复: 因为目前是在讲前端,所以就先不引入IR。
同时也是在告诉同学们,哪怕我们只拿到了AST,也已经能做很多事情了。
IR在后端部分会讲。我会给出一个自己设计的IR的例子,用IR重新实现部分功能。然后再去采用LLVM的IR。 2 ZYS2019-08-31宫老师,可否兼顾一下用c++的学员,介绍一下cpp版本playscript如何在visual studio2010或更高的版本运行?展开
ZYS2019-08-31宫老师,可否兼顾一下用c++的学员,介绍一下cpp版本playscript如何在visual studio2010或更高的版本运行?展开作者回复: 讲后端部分的时候,主要是用cpp版本实现的。那部分的指导资料我整理一下,写一个README.md,尽快更新到Github和码云上。
先简单说一下:
1.如果仅仅用cpp版本的Antlr,这个比较简单,你做练习的时候可以试用一下。
2.把Antlr和LLVM一起用的时候,要配置的东西更多一些,好在有cmake。 1 许童童2019-08-30变量的使用范围由作用域决定,作用域由词法规则决定,词法分析生成作用域链,之后查找变量就沿着这条作用域链查找,与函数调用栈就没有关系了。一般函数的生存期就是出栈后就结束了,如果是引用对象会在本次GC中回收,如果产生了闭包,那就要等到引用闭包的变量销毁,生存期才结束。展开
许童童2019-08-30变量的使用范围由作用域决定,作用域由词法规则决定,词法分析生成作用域链,之后查找变量就沿着这条作用域链查找,与函数调用栈就没有关系了。一般函数的生存期就是出栈后就结束了,如果是引用对象会在本次GC中回收,如果产生了闭包,那就要等到引用闭包的变量销毁,生存期才结束。展开作者回复: 很准确,很清晰!
1 沉淀的梦想2019-09-02用PlayScript的代码运行课程中的示例时会报一个空指针异常
沉淀的梦想2019-09-02用PlayScript的代码运行课程中的示例时会报一个空指针异常
String script = "int age = 44; for(int i = 0;i<10;i++) { age = age + 2;} int i = 8;";
Exception in thread "main" java.lang.NullPointerException
at play.ASTEvaluator.visitStatement(ASTEvaluator.java:617)
at play.ASTEvaluator.visitBlockStatement(ASTEvaluator.java:363)
at play.ASTEvaluator.visitBlockStatements(ASTEvaluator.java:723)
at play.ASTEvaluator.visitProg(ASTEvaluator.java:733)
at play.PlayScriptParser$ProgContext.accept(PlayScriptParser.java:2031)
at org.antlr.v4.runtime.tree.AbstractParseTreeVisitor.visit(AbstractParseTreeVisitor.java:18)
at play.PlayScriptCompiler.Execute(PlayScriptCompiler.java:28)
at play.PlayScript.main(PlayScript.java:98)展开作者回复: 1.是运行双引号内部的部分,不是连String script= 也带上。
2.是使用playscript-java这个工程吗?别用错了工程。
如果还有问题,继续给我提问!
希望不影响你继续动手实践的热情! 1 Geek_89bbab2019-09-01private void pushStack(StackFrame frame) {
Geek_89bbab2019-09-01private void pushStack(StackFrame frame) {
// 如果新加入的frame是当前frame的下一级,则入栈
if (stack.size() > 0) {
for (int i = stack.size()-1; i>0; i--){
StackFrame f = stack.get(i);
if (f.scope.enclosingScope == frame.scope.enclosingScope){
frame.parentFrame = f.parentFrame;
break;
}
else if (f.scope == frame.scope.enclosingScope){
frame.parentFrame = f;
break;
}
else if (frame.object instanceof FunctionObject){
FunctionObject functionObject = (FunctionObject)frame.object;
if (functionObject.receiver != null && functionObject.receiver.enclosingScope == f.scope) {
frame.parentFrame = f;
break;
}
}
}
if (frame.parentFrame == null){
frame.parentFrame = stack.peek();
}
}
stack.push(frame);
if (traceStackFrame){
dumpStackFrame();
}
}
老师可以解释一下这个函数吗?展开作者回复: 我往代码里加了注释,你可以更新一下看看!
我也把注释拷贝到这里。
里面有些特性,比如一等公民函数,是还没讲到的,10讲就会讲。
第一个if:
/*
如果新加入的栈桢,跟某个已有的栈桢的enclosingScope是一样的,那么这俩的parentFrame也一样。
因为它们原本就是同一级的嘛。
比如:
void foo(){};
void bar(foo());
或者:
void foo();
if (...){
foo();
}
*/
第二个if:
/*
如果新加入的栈桢,是某个已有的栈桢的下一级,那么就把把这个父子关系建立起来。比如:
void foo(){
if (...){ //把这个块往栈桢里加的时候,就符合这个条件。
}
}
再比如,下面的例子:
class MyClass{
void foo();
}
MyClass c = MyClass(); //先加Class的栈桢,里面有类的属性,包括父类的
c.foo(); //再加foo()的栈桢
*/
第3个if:
/*
这是针对函数可能是一等公民的情况。这个时候,函数运行时的作用域,与声明时的作用域会不一致。
我在这里设计了一个“receiver”的机制,意思是这个函数是被哪个变量接收了。要按照这个receiver的作用域来判断。
*/ 李懂2019-08-30原来栈里放的栈贞,栈贞是Scope,类似执行上下文,里面保存了变量!以前一直以为进栈,是放的执行函数体,跟上脚步!展开
李懂2019-08-30原来栈里放的栈贞,栈贞是Scope,类似执行上下文,里面保存了变量!以前一直以为进栈,是放的执行函数体,跟上脚步!展开作者回复: 这个栈桢还是拿java模拟的,让大家有个概念。到学后端的时候,那里有更物理的栈桢实现。到时候你可以进一步加深一下认识:-D
 北冥Master2019-08-30牛逼,越来越深入了,看的有点吃力了展开
北冥Master2019-08-30牛逼,越来越深入了,看的有点吃力了展开作者回复: 后几讲涉及的都是语义功能,并涉及了一部分运行期技术(给后端技术部分提前做铺垫)。
语义上的差别是每种语言真正的差别,但底层有一些共通的机制。搞搞明白对我们学各种语言都有好处。






