你好,我是 LMOS。
在前面的课程中,我们已经写好了 Cosmos 的进程管理组件,实现了多进程调度运行,今天我们一起探索 Linux 如何表示进程以及如何进行多进程调度。
好了,话不多说,我们开始吧。
Linux 如何表示进程
在 Cosmos 中,我们设计了一个 thread_t 数据结构来代表一个进程,Linux 也同样是用一个数据结构表示一个进程。
下面我们先来研究 Linux 的进程数据结构,然后看看 Linux 进程的地址空间数据结构,最后再来理解 Linux 的文件表结构。
Linux 进程的数据结构
Linux 系统下,把运行中的应用程序抽象成一个数据结构 task_struct,一个应用程序所需要的各种资源,如内存、文件等都包含在 task_struct 结构中。
因此,task_struct 结构是非常巨大的一个数据结构,代码如下。
为了帮你掌握核心思路,关于 task_struct 结构体,我省略了进程的权能、性能跟踪、信号、numa、cgroup 等相关的近 500 行内容,你若有兴趣可以自行阅读,这里你只需要明白,在内存中,一个 task_struct 结构体的实例变量代表一个 Linux 进程就行了。 创建 task_struct 结构
Linux 创建 task_struct 结构体的实例变量,这里我们只关注早期和最新的创建方式。
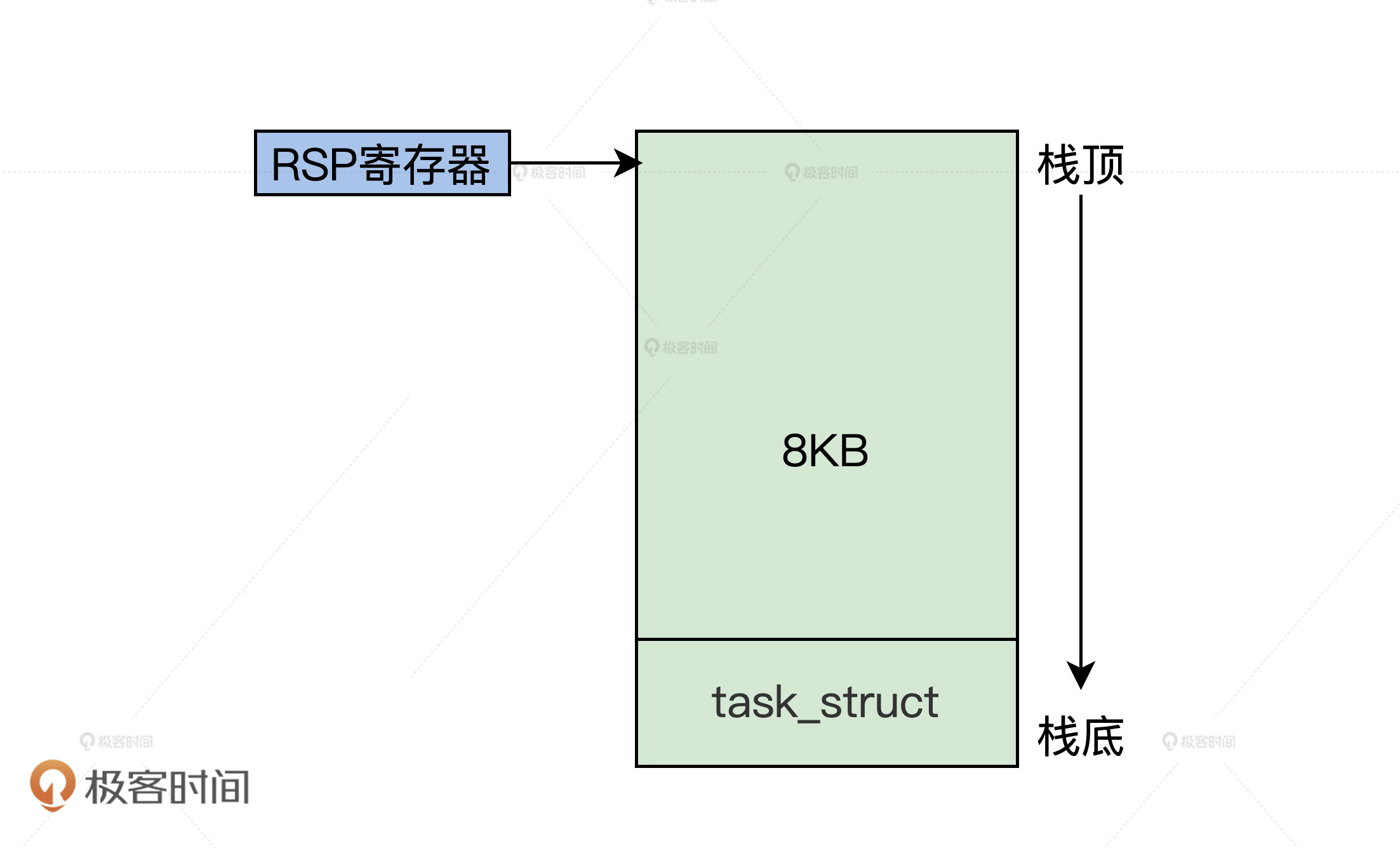
Linux 早期是这样创建 task_struct 结构体的实例变量的:找伙伴内存管理系统,分配两个连续的页面(即 8KB),作为进程的内核栈,再把 task_struct 结构体的实例变量,放在这 8KB 内存空间的开始地址处。内核栈则是从上向下伸长的,task_struct 数据结构是从下向上伸长的。
我给你画幅图,你就明白了。

进程内核栈
从图中不难发现,Linux 把 task_struct 结构和内核栈放在了一起 ,所以我们只要把 RSP 寄存器的值读取出来,然后将其低 13 位清零,就得到了当前 task_struct 结构体的地址。由于内核栈比较大,而且会向下伸长,覆盖掉 task_struct 结构体内容的概率就很小。
随着 Linux 版本的迭代,task_struct 结构体的体积越来越大,从前 task_struct 结构体和内核栈放在一起的方式就不合适了。最新的版本是分开放的,我们一起来看看后面的代码。
为了直击重点,我们不会讨论 Linux 的 fork 函数,你只要知道,它负责建立一个与父进程相同的进程,也就是复制了父进程的一系列数据,这就够了。
要复制父进程的数据必须要分配内存,上面代码的流程完整展示了从 SLAB 中分配 task_struct 结构,以及从伙伴内存系统分配内核栈的过程,整个过程是怎么回事儿,才是你要领会的重点。
Linux 进程地址空间
Linux 也是支持虚拟内存的操作系统内核,现在我们来看看 Linux 用于描述一个进程的地址空间的数据结构,它就是 mm_struct 结构,代码如下所示。
同样的,mm_struct 结构,我也精减了很多内容。其中的 vm_area_struct 结构,相当于我们之前 Cosmos 的 kmvarsdsc_t 结构(可以回看第 20 节课),是用来描述一段虚拟地址空间的。mm_struct 结构中也包含了 MMU 页表相关的信息。 下面我们一起来看看,mm_struct 结构是如何建立对应的实例变量呢?代码如下所示。
上述代码的 copy_mm 函数正是在 copy_process 函数中被调用的, copy_mm 函数调用 dup_mm 函数,把当前进程的 mm_struct 结构复制到 allocate_mm 宏分配的一个 mm_struct 结构中。这样,一个新进程的 mm_struct 结构就建立了。
Linux 进程文件表
在 Linux 系统中,可以说万物皆为文件,比如文件、设备文件、管道文件等。一个进程对一个文件进行读写操作之前,必须先打开文件,这个打开的文件就记录在进程的文件表中,它由 task_struct 结构中的 files 字段指向。这里指向的其实是个 files_struct 结构,代码如下所示。
从上述代码中,可以推想出我们在应用软件中调用:int fd = open("/tmp/test.txt"); 实际 Linux 会建立一个 struct file 结构体实例变量与文件对应,然后把 struct file 结构体实例变量的指针放入 fd_array 数组中。
那么 Linux 在建立一个新进程时,怎样给新进程建立一个 files_struct 结构呢?其实很简单,也是复制当前进程的 files_struct 结构,代码如下所示。
同样的,copy_files 函数由 copy_process 函数调用,copy_files 最终会复制当前进程的 files_struct 结构到一个新的 files_struct 结构实例变量中,并让新进程的 files 指针指向这个新的 files_struct 结构实例变量。
好了,关于进程的一些数据结构,我们就了解这么多,因为现在你还无需知道 Linux 进程的所有细节,对于一个庞大的系统,最大的误区是陷入细节而不知全貌。这里,我们只需要知道 Linux 用什么代表一个进程就行了。
Linux 进程调度
Linux 支持多 CPU 上运行多进程,这就要说到多进程调度了。Linux 进程调度支持多种调度算法,有基于优先级的调度算法,有实时调度算法,有完全公平调度算法(CFQ)。
下面我们以 CFQ 为例进行探讨,我们先了解一下 CFQ 相关的数据结构,随后探讨 CFQ 算法要怎样实现。
进程调度实体
我们先来看看什么是进程调度实体,它是干什么的呢?
它其实是 Linux 进程调度系统的一部分,被嵌入到了 Linux 进程数据结构中,与调度器进行关联,能间接地访问进程,这种高内聚低耦合的方式,保证了进程数据结构和调度数据结构相互独立,我们后面可以分别做改进、优化,这是一种高明的软件设计思想。我们来看看这个结构,代码如下所示。
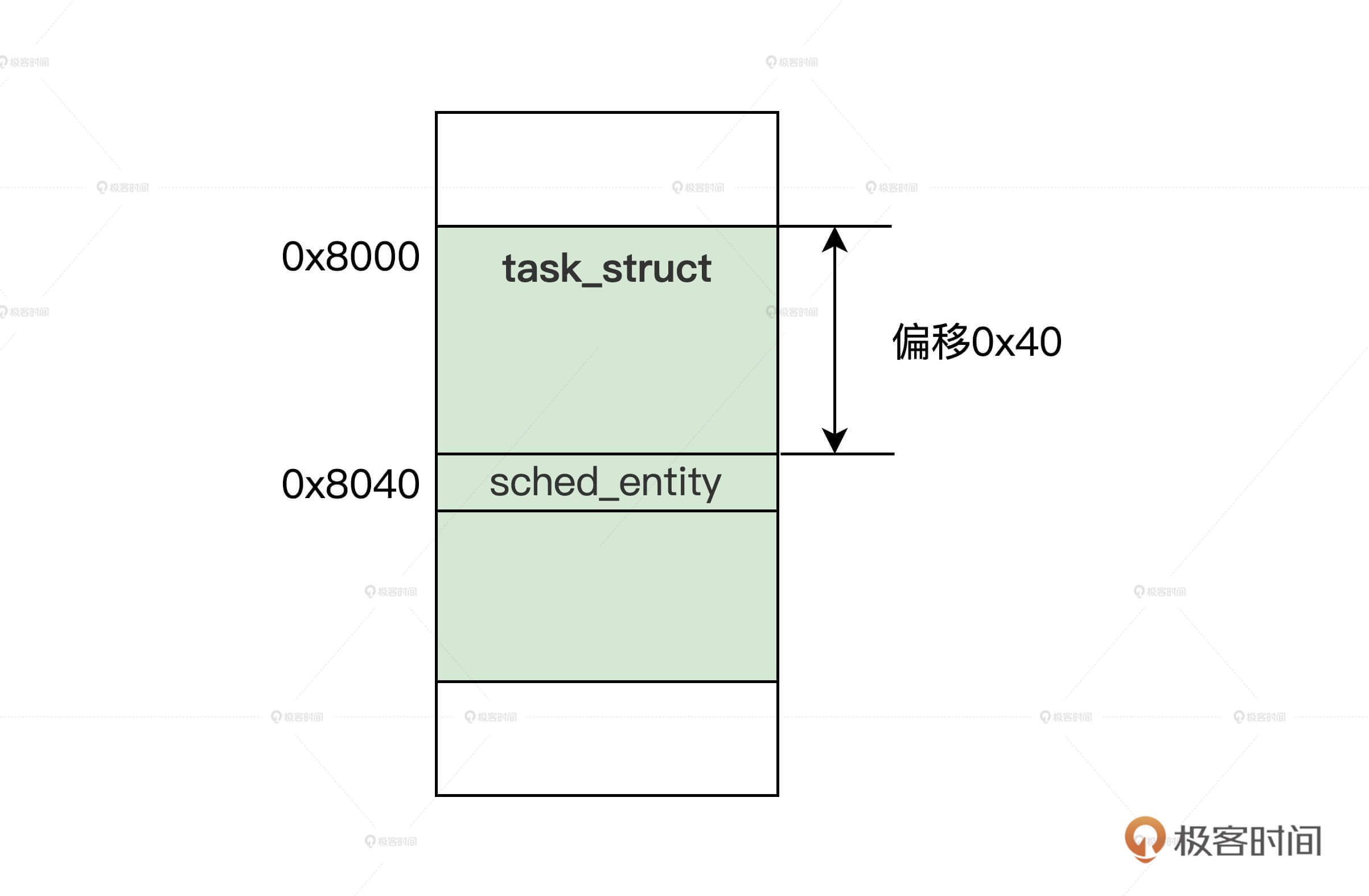
上述代码的信息量很多,但是我们现在不急于搞清楚所有的信息,我们现在需要知道的是在 task_struct 结构中,会包含至少一个 sched_entity 结构的变量,如下图所示。

调度实体在进程结构中的位置
结合图示,我们只要通过 sched_entity 结构变量的地址,减去它在 task_struct 结构中的偏移(由编译器自动计算),就能获取到 task_struct 结构的地址。这样就能达到通过 sched_entity 结构,访问 task_struct 结构的目的了。
进程运行队列
那么,在 Linux 中,又是怎样组织众多调度实体,进而组织众多进程,方便进程调度器找到调度实体呢?
首先,Linux 定义了一个进程运行队列结构,每个 CPU 分配一个这样的进程运行队列结构实例变量,进程运行队列结构的代码如下。
以上这个 rq 结构结构中,很多我们不需要关注的字段我已经省略了。你要重点理解的是,其中 task_struct 结构指针是为了快速访问特殊进程,而 rq 结构并不直接关联调度实体,而是包含了 cfs_rq、rt_rq、dl_rq,通过它们来关联调度实体。
有三个不同的运行队列,是因为作用于三种不同的调度算法。我们这里只需要关注 cfs_rq,代码我列在了后面。
为了简化问题,上述代码中我省略了调度组和负载相关的内容。你也许已经看出来了,其中 load、exec_clock、min_vruntime、tasks_timeline 字段是 CFS 调度算法得以实现的关键,你甚至可以猜出所有的调度实体,都是通过红黑树组织起来的,即 cfs_rq 结构中的 tasks_timeline 字段。
调度实体和运行队列的关系
相信我,作为初学者,了解数据结构之间的组织关系,这远比了解一个数据结构所有字段的作用和细节重要得多。
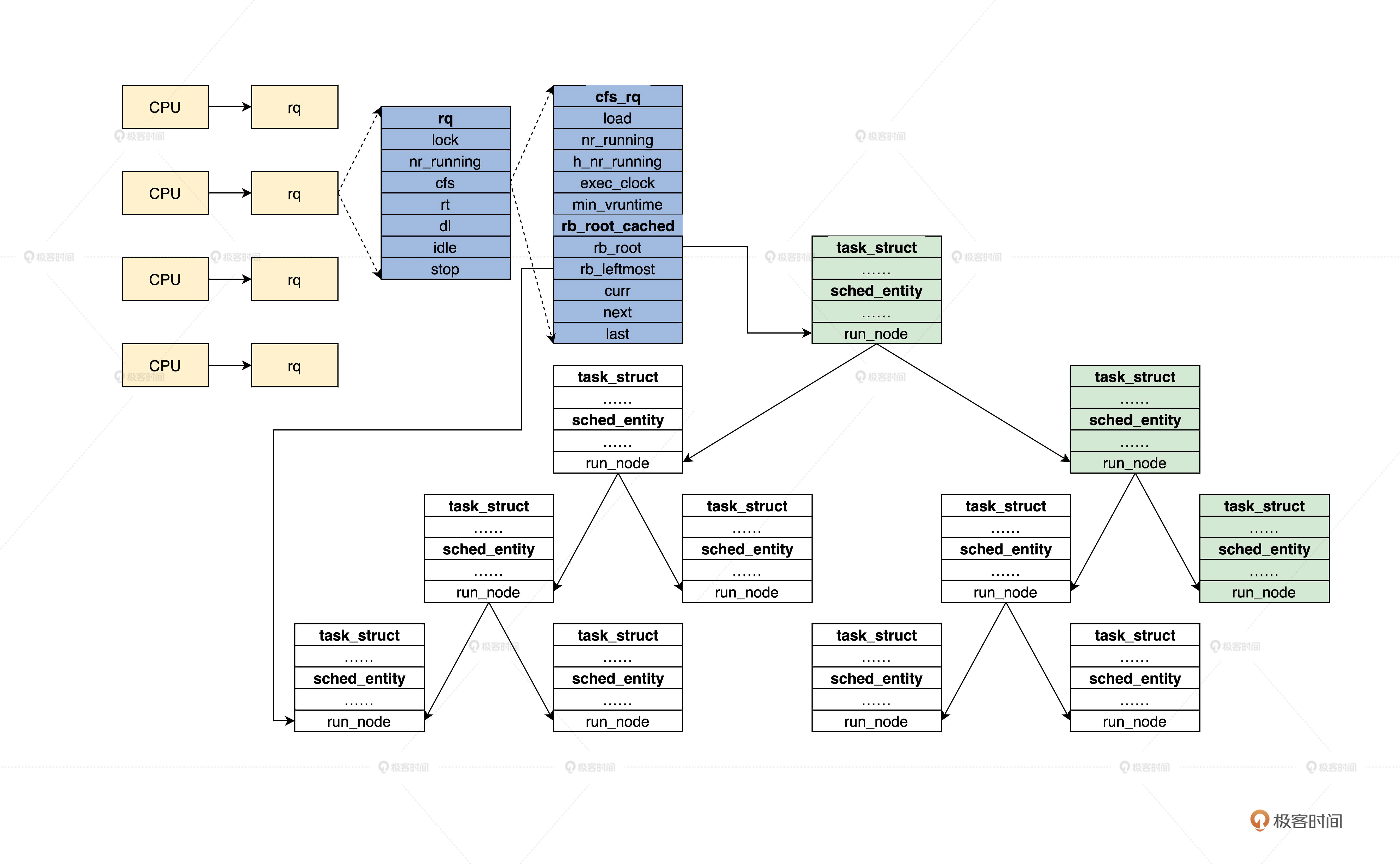
通过前面的学习,我们已经了解了 rq、cfs_rq、rb_root_cached、sched_entity、task_struct 等数据结构,下面我们来看看它的组织关系,我特意为你准备了后面这幅图。

运行队列框架示意图
结合图片我们发现,task_struct 结构中包含了 sched_entity 结构。sched_entity 结构是通过红黑树组织起来的,红黑树的根在 cfs_rq 结构中,cfs_rq 结构又被包含在 rq 结构,每个 CPU 对应一个 rq 结构。这样,我们就把所有运行的进程组织起来了。
调度器类
从前面的 rq 数据结构中,你已经发现了,Linux 是同时支持多个进程调度器的,不同的进程挂载到不同的运行队列中,如 rq 结构中的 cfs、rt、dl,然后针对它们这些结构,使用不同的调度器。
为了支持不同的调度器,Linux 定义了调度器类数据结构,它定义了一个调度器要实现哪些函数,代码如下所示。
这个 sched_class 结构定义了一组函数指针,为了让你抓住重点,这里我删除了调度组和负载均衡相关的函数指针。Linux 系统一共定义了五个 sched_class 结构的实例变量,这五个 sched_class 结构紧靠在一起,形成了 sched_class 结构数组。
为了找到相应的 sched_class 结构实例,可以用以下代码遍历所有的 sched_class 结构实例变量。
这些类是有优先级的,它们的优先级是:stop_sched_class > dl_sched_class > rt_sched_class > fair_sched_class > idle_sched_class。
下面我们观察一下,CFS 调度器(这个调度器我们稍后讨论)所需要的 fair_sched_class,代码如下所示。
const struct sched_class fair_sched_class
__section("__fair_sched_class") = {
.enqueue_task = enqueue_task_fair,
.dequeue_task = dequeue_task_fair,
.check_preempt_curr = check_preempt_wakeup,
.pick_next_task = __pick_next_task_fair,
};
我们看到这些函数指针字段都对应到了具体的函数。其实,实现一个新的调度器,就是实现这些对应的函数。好了,我们清楚了调度器类,它就是一组函数指针,不知道你发现没有,这难道不是 C 语言下的面向对象吗?下面,我们接着研究 CFS 调度器。
Linux 的 CFS 调度器
Linux 支持多种不同的进程调度器,比如 RT 调度器、Deadline 调度器、CFS 调度器以及 Idle 调度器。不过,这里我们仅仅讨论一下 CFS 调度器,也就是完全公平调度器,CFS 的设计理念是在有限的真实硬件平台上模拟实现理想的、精确的多任务 CPU。现在你不懂也不要紧,我们后面会讨论的。
在了解 CFS 核心算法之前,你需要先掌握几个核心概念。
普通进程的权重
Linux 会使用 CFS 调度器调度普通进程,CFS 调度器与其它进程调度器的不同之处在于没有时间片的概念,它是分配 CPU 使用时间的比例。比如,4 个相同优先级的进程在一个 CPU 上运行,那么每个进程都将会分配 25% 的 CPU 运行时间。这就是进程要的公平。
然而事有轻重缓急,对进程来说也是一样,有些进程的优先级就需要很高。那么 CFS 调度器是如何在公平之下,实现“不公平”的呢?
首先,CFS 调度器下不叫优先级,而是叫权重,权重表示进程的优先级,各个进程按权重的比例分配 CPU 时间。
举个例子,现在有 A、B 两个进程。进程 A 的权重是 1024,进程 B 的权重是 2048。那么进程 A 获得 CPU 的时间比例是 1024/(1024+2048) = 33.3%。进程 B 获得的 CPU 时间比例是 2048/(1024+2048)=66.7%。
因此,权重越大,分配的时间比例越大,就相当于进程的优先级越高。
有了权重之后,分配给进程的时间计算公式如下:
进程的时间 = CPU 总时间 * 进程的权重 / 就绪队列所有进程权重之和
但是进程对外的编程接口中使用的是一个 nice 值,大小范围是(-20~19),数值越小优先级越大,意味着权重值越大,nice 值和权重之间可以转换的。Linux 提供了后面这个数组,用于转换 nice 值和权重。
一个进程每降低一个 nice 值,就能多获得 10% 的 CPU 时间。1024 权重对应 nice 值为 0,被称为 NICE_0_LOAD。默认情况下,大多数进程的权重都是 NICE_0_LOAD。
进程调度延迟
了解了进程权重,现在我们看看进程调度延迟,什么是调度延迟?其实就是保证每一个可运行的进程,都至少运行一次的时间间隔。
我们结合实例理解,系统中有 3 个可运行进程,每个进程都运行 10ms,那么调度延迟就是 30ms;如果有 10 个进程,那么调度延迟就是 100ms;如果现在保证调度延迟不变,固定是 30ms;如果系统中有 3 个进程,则每个进程可运行 10ms;如果有 10 个进程,则每个进程可运行 3ms。
随着进程的增加,每个进程分配的时间在减少,进程调度次数会增加,调度器占用的时间就会增加。因此,CFS 调度器的调度延迟时间的设定并不是固定的。
当运行进程少于 8 个的时候,调度延迟是固定的 6ms 不变。当运行进程个数超过 8 个时,就要保证每个进程至少运行一段时间,才被调度。这个“至少一段时间”叫作最小调度粒度时间。
在 CFS 默认设置中,最小调度粒度时间是 0.75ms,用变量 sysctl_sched_min_granularity 记录。由 __sched_period 函数负责计算,如下所示。
上述代码中,参数 nr_running 是 Linux 系统中可运行的进程数量,当超过 sched_nr_latency 时,我们无法保证调度延迟,因此转为保证最小调度粒度。
虚拟时间
你是否还记得调度实体中的 vruntime 么?它就是用来表示虚拟时间的,我们先按下不表,来看一个例子。
假设幼儿园只有一个秋千,所有孩子都想玩,身为老师的你该怎么处理呢?你一定会想每个孩子玩一段时间,然后就让给别的孩子,依次类推。CFS 调度器也是这样做的,它记录了每个进程的执行时间,为保证每个进程运行时间的公平,哪个进程运行的时间最少,就会让哪个进程运行。

CFS调度器原理
例如,调度延迟是 10ms,系统一共 2 个相同优先级的进程,那么各进程都将在 10ms 的时间内各运行 5ms。
现在进程 A 和进程 B 他们的权重分别是 1024 和 820(nice 值分别是 0 和 1)。进程 A 获得的运行时间是 10x1024/(1024+820)=5.6ms,进程 B 获得的执行时间是 10x820/(1024+820)=4.4ms。进程 A 的 cpu 使用比例是 5.6/10x100%=56%,进程 B 的 cpu 使用比例是 4.4/10x100%=44%。
很明显,这两个进程的实际执行时间是不等的,但 CFS 调度器想保证每个进程的运行时间相等。因此 CFS 调度器引入了虚拟时间,也就是说,上面的 5.6ms 和 4.4ms 经过一个公式,转换成相同的值,这个转换后的值就叫虚拟时间。这样的话,CFS 只需要保证每个进程运行的虚拟时间是相等的。
虚拟时间 vruntime 和实际时间(wtime)转换公式如下:
vruntime = wtime*( NICE_0_LOAD/weight)
根据上面的公式,可以发现 nice 值为 0 的进程,这种进程的虚拟时间和实际时间是相等的,那么进程 A 的虚拟时间为:5.6*(1024/1024)=5.6,进程 B 的虚拟时间为:4.4*(1024/820)=5.6。虽然进程 A 和进程 B 的权重不一样,但是计算得到的虚拟时间是一样的。
所以,CFS 调度主要保证每个进程运行的虚拟时间一致即可。在选择下一个即将运行的进程时,只需要找到虚拟时间最小的进程就行了。这个计算过程由 calc_delta_fair 函数完成,如下所示。
按照上面的理论,调用 __calc_delta 函数的时候,传递的 weight 参数是 NICE_0_LOAD,lw 参数正是调度实体中的 load_weight 结构体。
到这里,我要公开一个问题,在运行队列中用红黑树结构组织进程的调度实体,这里进程虚拟时间正是红黑树的 key,这样进程就以进程的虚拟时间被红黑树组织起来了。红黑树的最左子节点,就是虚拟时间最小的进程,随着时间的推移进程会从红黑树的左边跑到右,然后从右边跑到左边,就像舞蹈一样优美。
CFS 调度进程
根据前面的内容,我们得知 CFS 调度器就是要维持各个可运行进程的虚拟时间相等,不相等就需要被调度运行。如果一个进程比其它进程的虚拟时间小,它就应该运行达到和其它进程的虚拟时间持平,直到它的虚拟时间超过其它进程,这时就要停下来,这样其它进程才能被调度运行。
定时周期调度
前面虚拟时间的方案还存在问题,你发现了么?
没错,虚拟时间就是一个数据,如果没有任何机制对它进行更新,就会导致一个进程永远运行下去,因为那个进程的虚拟时间没有更新,虚拟时间永远最小,这当然不行。
因此定时周期调度机制应运而生。Linux 启动会启动定时器,这个定时器每 1/1000、1/250、1/100 秒(根据配置不同选取其一),产生一个时钟中断,在中断处理函数中最终会调用一个 scheduler_tick 函数,代码如下所示。
上述代码中,scheduler_tick 函数会调用进程调度类的 task_tick 函数,对于 CFS 调度器就是 task_tick_fair 函数。但是真正做事的是 entity_tick 函数,entity_tick 函数中调用了 update_curr 函数更新当前进程虚拟时间,这个函数我们在之前讨论过了,还更新了运行队列的相关数据。
entity_tick 函数的最后,调用了 check_preempt_tick 函数,用来检查是否可以抢占调度,代码如下。
刚才的代码你可以这样理解,如果需要抢占就会调用 resched_curr 函数设置进程的抢占标志,但是这个函数本身不会调用进程调度器函数,而是在进程从中断或者系统调用返回到用户态空间时,检查当前进程的调度标志,然后根据需要调用进程调度器函数。
调度器入口
如果设计需要进行进程抢占调度,Linux 就会在适当的时机进行进程调度,进程调度就是调用进程调度器入口函数,该函数会选择一个最合适投入运行的进程,然后切换到该进程上运行。
我们先来看看,进程调度器入口函数的代码长什么样。
之所以在循环中调用 __schedule 函数执行真正的进程调度,是因为在执行调度的过程中,有些更高优先级的进程进入了可运行状态,因此它就要抢占当前进程。
__schedule 函数中会更新一些统计数据,然后调用 pick_next_task 函数挑选出下一个进程投入运行。最后,如果当前进程和下一个要运行的进程不同,就要进行进程机器上下文切换,其中会切换地址空间和 CPU 寄存器。
挑选下一个进程
在 __schedule 函数中,获取了正在运行的进程,更新了运行队列的时钟,下面就要挑选出下一个投入运行的进程。显然,不是随便挑选一个,我们这就来看看调度器是如何挑选的。
挑选下一个运行进程这个过程,是在 pick_next_task 函数中完成的,如下所示。
你看,pick_next_task 函数只是个框架函数,它的逻辑也很清楚,会依照优先级调用具体调度器类的函数完成工作,对于 CFS 则会调用 pick_next_task_fair 函数,代码如下所示。
上述代码中调用 pick_next_entity 函数选择虚拟时间最小的调度实体,然后调用 set_next_entity 函数,对选择的调度实体进行一些必要的处理,主要是将这调度实体从运行队列中拿出来。
pick_next_entity 函数具体要怎么工作呢?
首先,它调用了相关函数,从运行队列上的红黑树中查找虚拟时间最少的调度实体,然后处理要跳过调度的情况,最后决定挑选的调度实体是否可以抢占并返回它。
代码的调用路径最终会返回到 __schedule 函数中,这个函数中就是上一个运行的进程和将要投入运行的下一个进程,最后调用 context_switch 函数,完成两个进程的地址空间和机器上下文的切换,一次进程调度工作结束。这个机制和我们的 Cosmos 的 save_to_new_context 函数类似,不再赘述。
至此 CFS 调度器的基本概念与数据结构,还有算法实现,我们就搞清楚了,核心就是让虚拟时间最小的进程最先运行, 一旦进程运行虚拟时间就会增加,最后尽量保证所有进程的虚拟时间相等,谁小了就要多运行,谁大了就要暂停运行。
重点回顾
Linux 如何表示一个进程以及如何进行多个进程调度,我们已经搞清楚了。我们来总结一下。
你可能在想。为什么要用红黑树来组织调度实体?这是因为要维护虚拟时间的顺序,又要从中频繁的删除和插入调度实体,这种情况下红黑树这种结构无疑是非常好,如果你有更好的选择,可以向 Linux 社区提交补丁。
思考题
想一想,Linux 进程的优先级和 Linux 调度类的优先级是一回事儿吗?
欢迎你在留言区记录你的学习经验或者个我交流讨论,也欢迎你把这节课转发给需要的朋友。
好,我是 LMOS,我们下节课见!